 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Cleaning for the MSR-Video to Text Dataset
Paper and Code

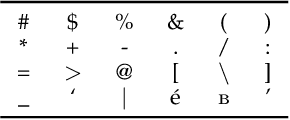


The video captioning task is to describe the video contents with natural language by the machine. Many methods have been proposed for solving this task. A large dataset called MSR Video to Text (MSR-VTT) is often used as the benckmark dataset for testing the performance of the methods. However, we found that the human annotations, i.e., the descriptions of video contents in the dataset are quite noisy, e.g., there are many duplicate captions and many captions contain grammatical problems. These problems may pose difficulties to video captioning models for learning. We cleaned the MSR-VTT annotations by removing these problems, then tested several typical video captioning models on the cleaned dataset. Experimental results showed that data cleaning boosted the performances of the models measured by popular quantitative metrics. We recruited subjects to evaluate the results of a model trained on the original and cleaned datasets. The human behavior experiment demonstrated that trained on the cleaned dataset, the model generated captions that were more coherent and more relevant to contents of the video clips. The cleaned dataset is publicly available.