 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-Theoretic Analysis for Transfer Learning: Error Bounds and Applications
Paper and Code
Jul 12, 2022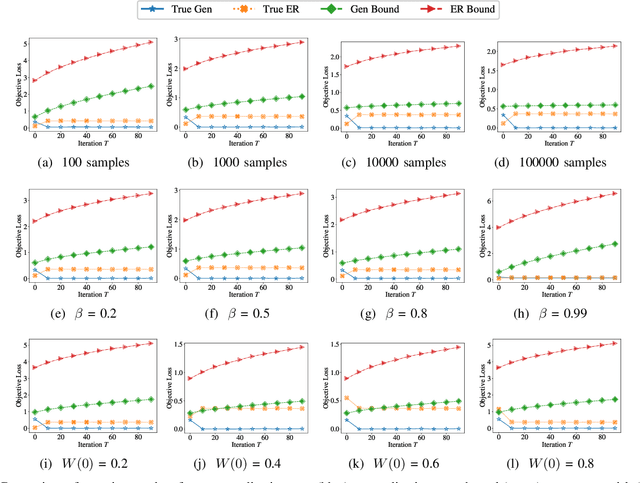
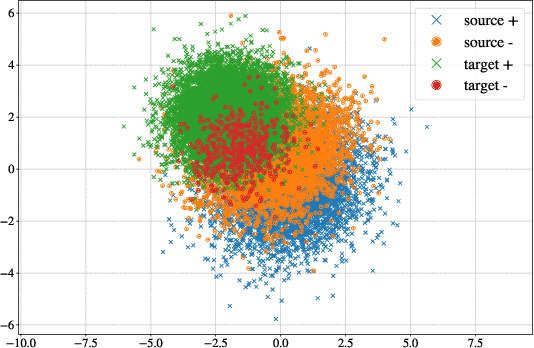
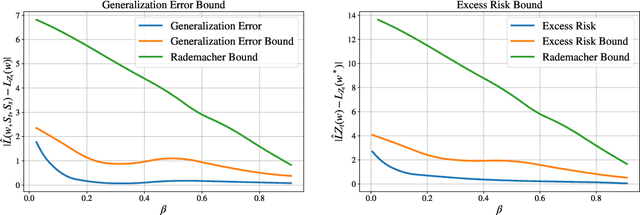
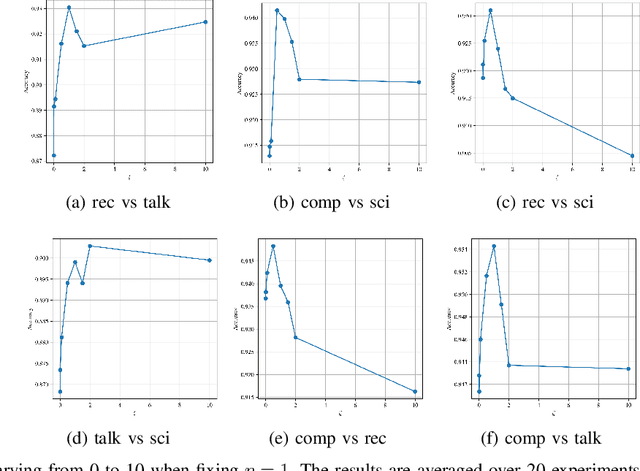
Transfer learning, or domain adaptation, is concerned with machine learning problems in which training and testing data come from possibly different probability distributions. In this work, we give an information-theoretic analysis on the generalization error and excess risk of transfer learning algorithms, following a line of work initiated by Russo and Xu. Our results suggest, perhaps as expected, that the Kullback-Leibler (KL) divergence $D(\mu||\mu')$ plays an important role in the characterizations where $\mu$ and $\mu'$ denote the distribution of the training data and the testing test, respectively. Specifically, we provide generalization error upper bounds for the empirical risk minimization (ERM) algorithm where data from both distributions are available in the training phase. We further apply the analysis to approximated ERM methods such as the Gibbs algorithm and the stochastic gradient descent method. We then generalize the mutual information bound with $\phi$-divergence and Wasserstein distance. These generalizations lead to tighter bounds and can handle the case when $\mu$ is not absolutely continuous with respect to $\mu'$. Furthermore, we apply a new set of techniques to obtain an alternative upper bound which gives a fast (and optimal) learning rate for some learning problems. Finally, inspired by the derived bounds, we propose the InfoBoost algorithm in which the importance weights for source and target data are adjusted adaptively in accordance to information measures. The empirical results show the effectiveness of the proposed algorithm.