 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Self-Supervised Pre-Training for Skin-Lesion Analysis
Paper and Code
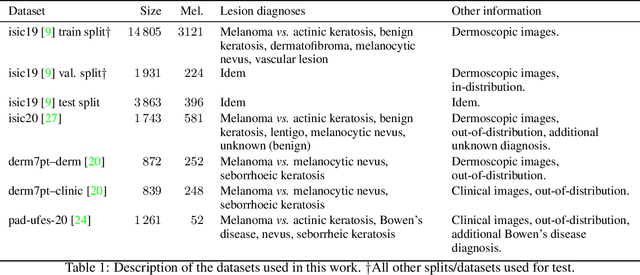
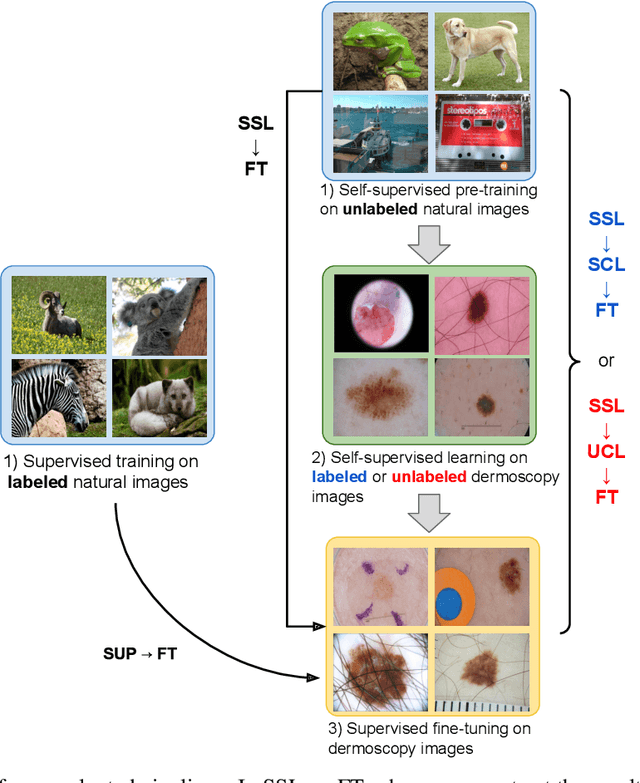

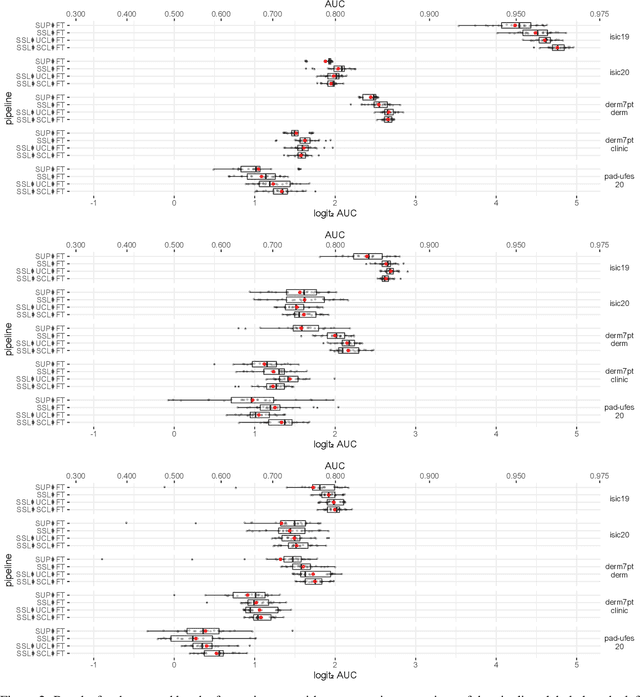
Self-supervised pre-training appears as an advantageous alternative to supervised pre-trained for transfer learning. By synthesizing annotations on pretext tasks, self-supervision allows to pre-train models on large amounts of pseudo-labels before fine-tuning them on the target task. In this work, we assess self-supervision for the diagnosis of skin lesions, comparing three self-supervised pipelines to a challenging supervised baseline, on five test datasets comprising in- and out-of-distribution samples. Our results show that self-supervision is competitive both in improving accuracies and in reducing the variability of outcomes. Self-supervision proves particularly useful for low training data scenarios ($<1\,500$ and $<150$ samples), where its ability to stabilize the outcomes is essential to provide sound results.