 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble of Convolutional Neural Networks for Audio Classification
Paper and Code
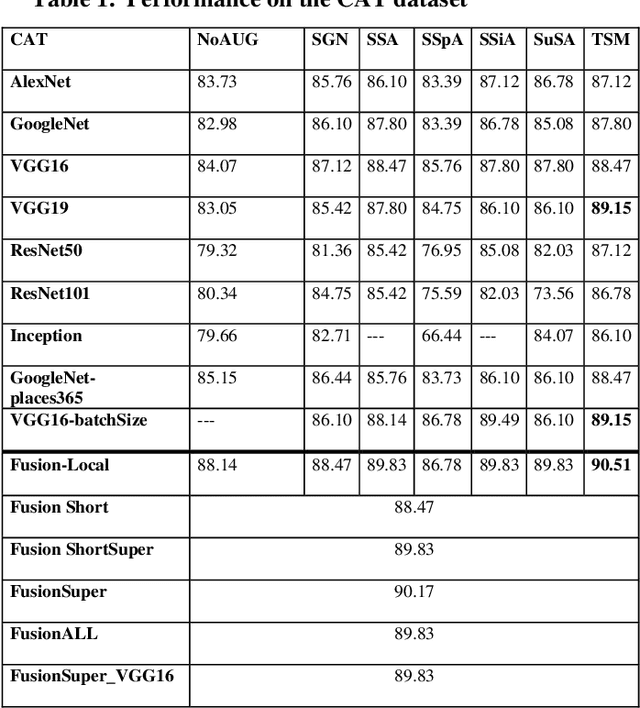

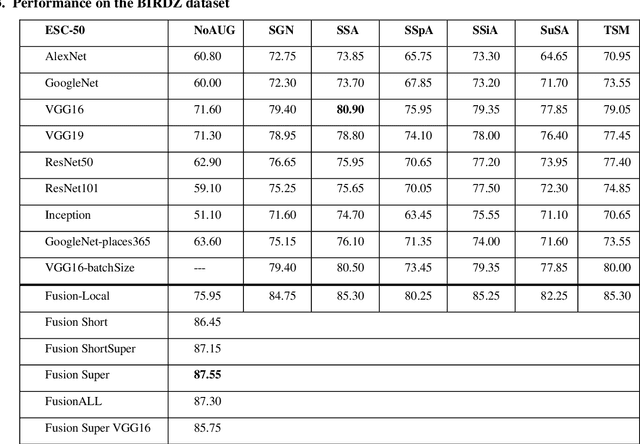
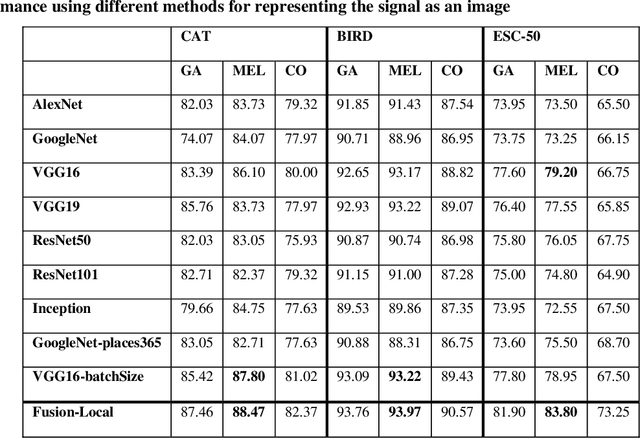
In this paper, ensembles of classifiers that exploit several data augmentation techniques and four signal representations for training Convolutional Neural Networks (CNNs) for audio classification are presented and tested on three freely available audio classification datasets: i) bird calls, ii) cat sounds, and iii) the Environmental Sound Classification dataset. The best performing ensembles combining data augmentation techniques with different signal representations are compared and shown to outperform the best methods reported in the literature on these datasets. The approach proposed here obtains state-of-the-art results in the widely used ESC-50 dataset. To the best of our knowledge, this is the most extensive study investigating ensembles of CNNs for audio classification. Results demonstrate not only that CNNs can be trained for audio classification but also that their fusion using different techniques works better than the stand-alone classifiers.