 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical study of the effect of background data size on the stability of SHapley Additive exPlanations for deep learning models
Paper and Code

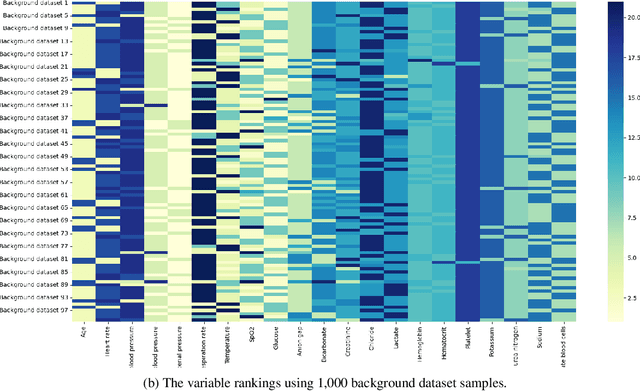
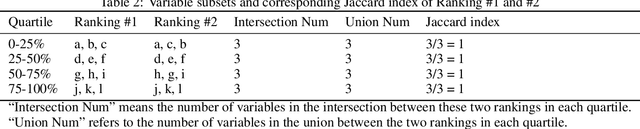
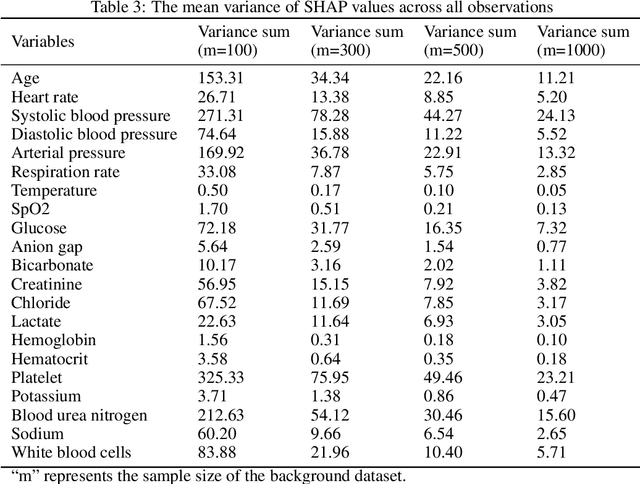
Nowadays, the interpretation of why a machine learning (ML) model makes certain inferences is as crucial as the accuracy of such inferences. Some ML models like the decision tree possess inherent interpretability that can be directly comprehended by humans. Others like artificial neural networks (ANN), however, rely on external methods to uncover the deduction mechanism. SHapley Additive exPlanations (SHAP) is one of such external methods, which requires a background dataset when interpreting ANNs. Generally, a background dataset consists of instances randomly sampled from the training dataset. However, the sampling size and its effect on SHAP remain to be unexplored. In our empirical study on the MIMIC-III dataset, we show that the two core explanations - SHAP values and variable rankings fluctuate when using different background datasets acquired from random sampling, indicating that users cannot unquestioningly trust the one-shot interpretation from SHAP. Luckily, such fluctuation decreases with the increase of the background dataset size. Also, we notice an U-shape in the stability assessment of SHAP variable rankings, demonstrating that SHAP is more reliable in ranking the most and least important variables compared to moderately important ones. Overall, our results suggest that users should take into account how background data affects SHAP results, with improved SHAP stability as the background sample size increases.