 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis Of Protected Health Information Leakage In Deep-Learning Based De-Identification Algorithms
Paper and Code
Jan 28, 2021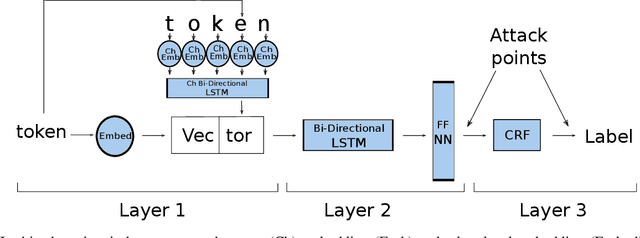
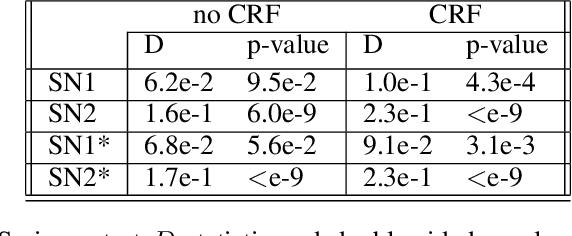
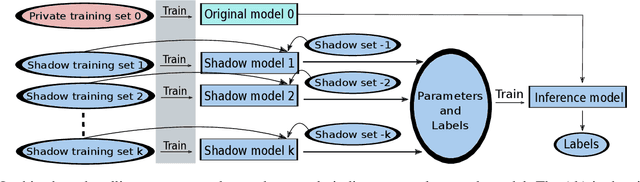
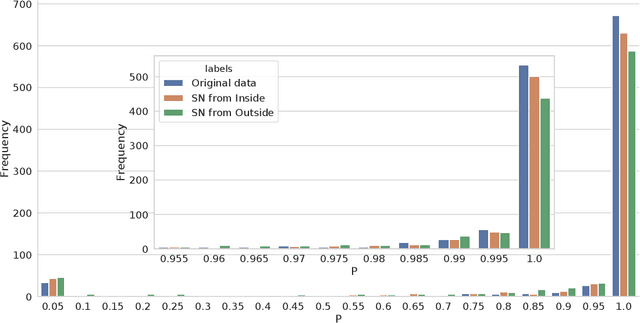
The increasing complexity of algorithms for analyzing medical data, including de-identification tasks, raises the possibility that complex algorithms are learning not just the general representation of the problem, but specifics of given individuals within the data. Modern legal frameworks specifically prohibit the intentional or accidental distribution of patient data, but have not addressed this potential avenue for leakage of such protected health information. Modern deep learning algorithms have the highest potential of such leakage due to complexity of the models. Recent research in the field has highlighted such issues in non-medical data, but all analysis is likely to be data and algorithm specific. We, therefore, chose to analyze a state-of-the-art free-text de-identification algorithm based on LSTM (Long Short-Term Memory) and its potential in encoding any individual in the training set. Using the i2b2 Challenge Data, we trained, then analyzed the model to assess whether the output of the LSTM, before the compression layer of the classifier, could be used to estimate the membership of the training data. Furthermore, we used different attacks including membership inference attack method to attack the model. Results indicate that the attacks could not identify whether members of the training data were distinguishable from non-members based on the model output. This indicates that the model does not provide any strong evidence into the identification of the individuals in the training data set and there is not yet empirical evidence it is unsafe to distribute the model for general use.