 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-Optical Information Processing Capacity of Diffractive Surfaces
Paper and Code
Jul 25, 2020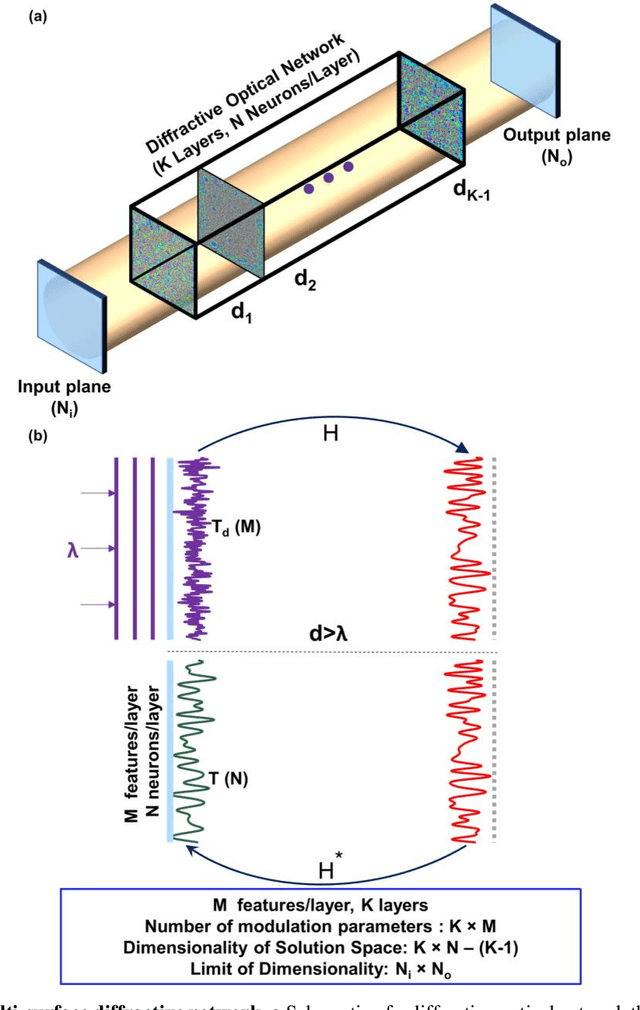

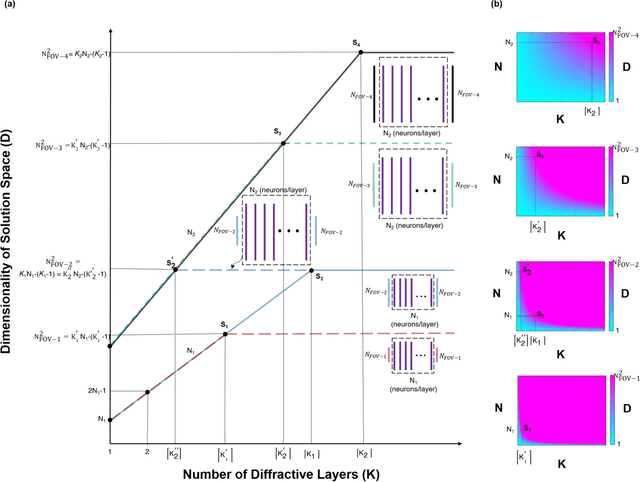

Precise engineering of materials and surfaces has been at the heart of some of the recent advances in optics and photonics. These advances around the engineering of materials with new functionalities have also opened up exciting avenues for designing trainable surfaces that can perform computation and machine learning tasks through light-matter interaction and diffraction. Here, we analyze the information processing capacity of coherent optical networks formed by diffractive surfaces that are trained to perform an all-optical computational task between a given input and output field-of-view. We prove that the dimensionality of the all-optical solution space covering the complex-valued transformations between the input and output fields-of-view is linearly proportional to the number of diffractive surfaces within the optical network, up to a limit that is dictated by the extent of the input and output fields-of-view. Deeper diffractive networks that are composed of larger numbers of trainable surfaces can cover a higher dimensional subspace of the complex-valued linear transformations between a larger input field-of-view and a larger output field-of-view, and exhibit depth advantages in terms of their statistical inference, learning and generalization capabilities for different image classification tasks, when compared with a single trainable diffractive surface. These analyses and conclusions are broadly applicable to various forms of diffractive surfaces, including e.g., plasmonic and/or dielectric-based metasurfaces and flat optics that can be used to form all-optical processors.