 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALA: Adversarial Lightness Attack via Naturalness-aware Regularizations
Paper and Code
Jan 16, 2022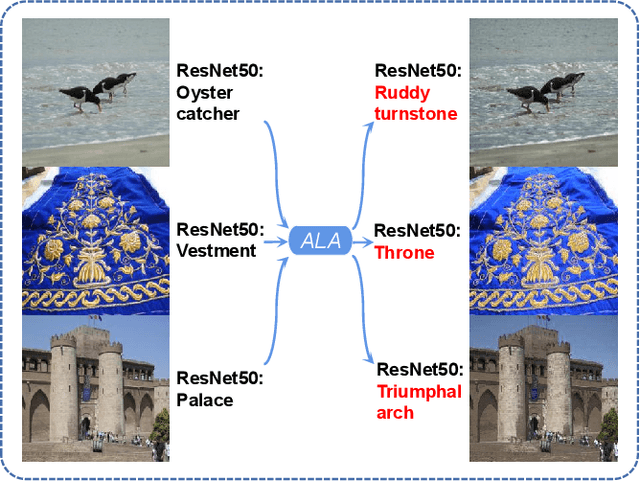
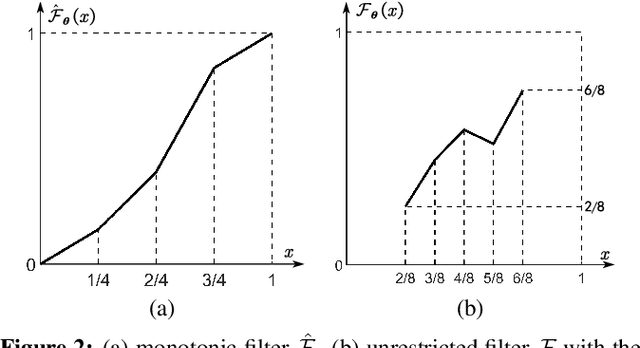
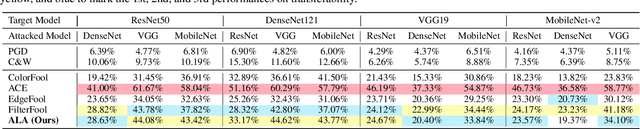
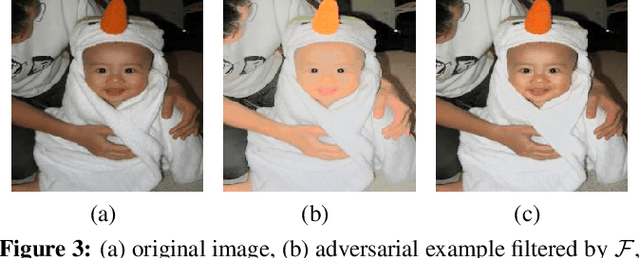
Most researchers have tried to enhance the robustness of deep neural networks (DNNs) by revealing and repairing the vulnerability of DNNs with specialized adversarial examples. Parts of the attack examples have imperceptible perturbations restricted by Lp norm. However, due to their high-frequency property, the adversarial examples usually have poor transferability and can be defensed by denoising methods. To avoid the defects, some works make the perturbations unrestricted to gain better robustness and transferability. However, these examples usually look unnatural and alert the guards. To generate unrestricted adversarial examples with high image quality and good transferability, in this paper, we propose Adversarial Lightness Attack (ALA), a white-box unrestricted adversarial attack that focuses on modifying the lightness of the images. The shape and color of the samples, which are crucial to human perception, are barely influenced. To obtain adversarial examples with high image quality, we craft a naturalness-aware regularization. To achieve stronger transferability, we propose random initialization and non-stop attack strategy in the attack procedure. We verify the effectiveness of ALA on two popular datasets for different tasks (i.e., ImageNet for image classification and Places-365 for scene recognition). The experiments show that the generated adversarial examples have both strong transferability and high image quality. Besides, the adversarial examples can also help to improve the standard trained ResNet50 on defending lightness corruption.