 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Preference Optimization
Paper and Code
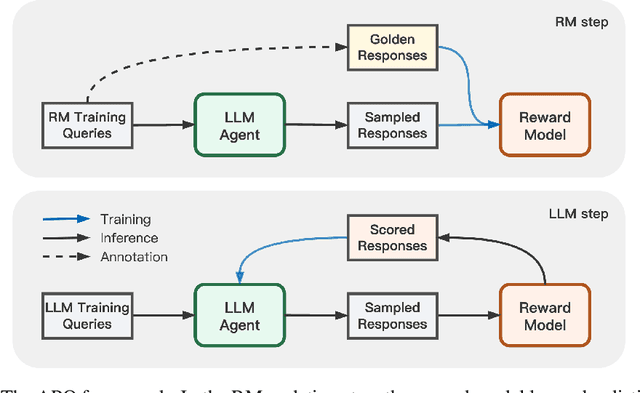

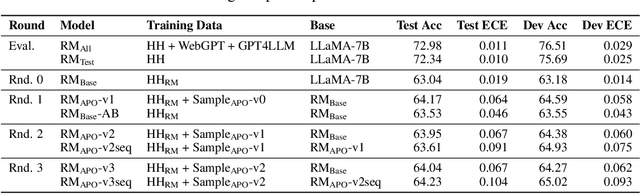
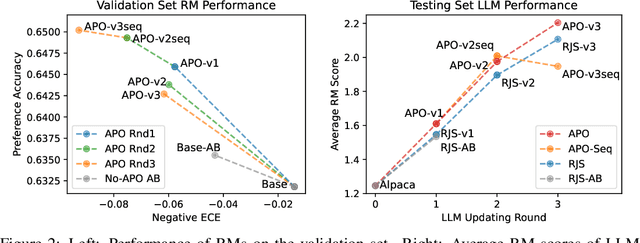
Human preference alignment is a crucial training step to improve the interaction quality of large language models (LLMs). Existing aligning methods depend on manually annotated preference data to guide the LLM optimization directions. However, in practice, continuously updating LLMs raises a distribution gap between model-generated samples and human-preferred responses, which hinders model fine-tuning efficiency. To mitigate this issue, previous methods require additional preference annotation on generated samples to adapt the shifted distribution, which consumes a large amount of annotation resources. Targeting more efficient human preference optimization, we propose an adversarial preference optimization (APO) framework, where the LLM agent and the preference model update alternatively via a min-max game. Without additional annotation, our APO method can make a self-adaption to the generation distribution gap through the adversarial learning process. In experiments, we empirically verify the effectiveness of APO in improving LLM's helpfulness and harmlessness compared with rejection sampling baselines.