 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADM for grid CRF loss in CNN segmentation
Paper and Code
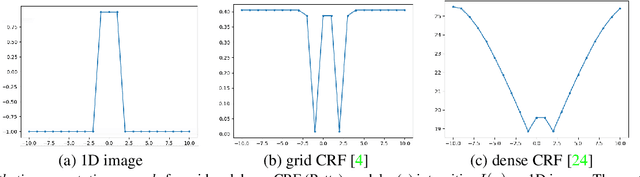
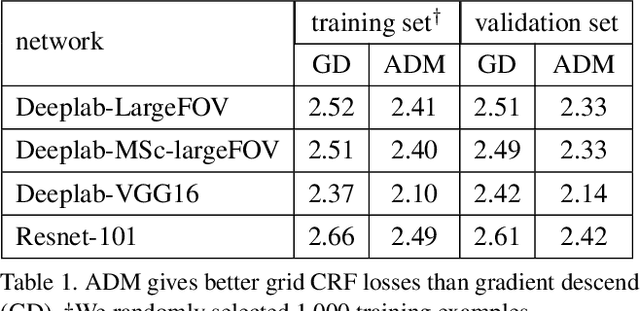

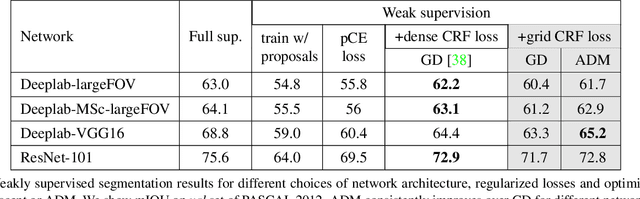
Variants of gradient descent (GD) dominate CNN loss minimization in computer vision. But, as we show, some powerful loss functions are practically useless only due to their poor optimization by GD. In the context of weakly-supervised CNN segmentation, we present a general ADM approach to regularized losses, which are inspired by well-known MRF/CRF models in "shallow" segmentation. While GD fails on the popular nearest-neighbor Potts loss, ADM splitting with $\alpha$-expansion solver significantly improves optimization of such grid CRF losses yielding state-of-the-art training quality. Denser CRF losses become amenable to basic GD, but they produce lower quality object boundaries in agreement with known noisy performance of dense CRF inference in shallow segmentation.