 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Mimic: Deep Reinforcement Learning of Parameterized Bipedal Walking from Infeasible References
Paper and Code
Dec 13, 2021
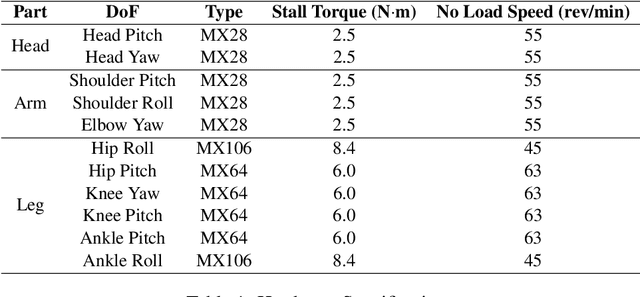
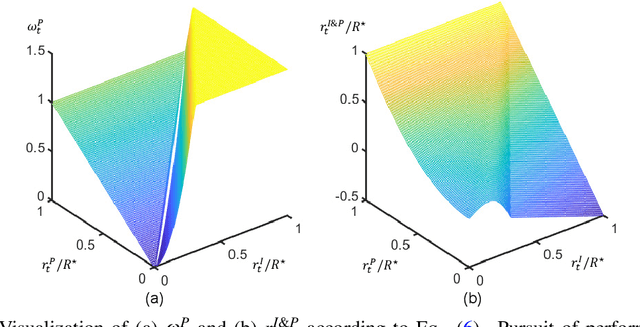
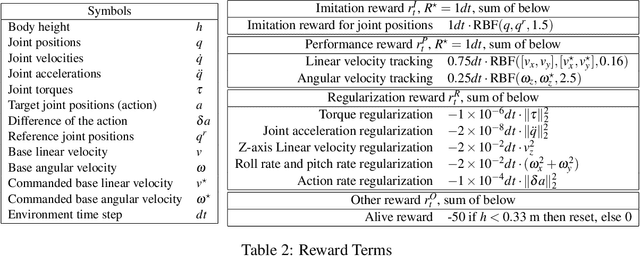
Not until recently, robust robot locomotion has been achieved by deep reinforcement learning (DRL). However, for efficient learning of parametrized bipedal walking, developed references are usually required, limiting the performance to that of the references. In this paper, we propose to design an adaptive reward function for imitation learning from the references. The agent is encouraged to mimic the references when its performance is low, while to pursue high performance when it reaches the limit of references. We further demonstrate that developed references can be replaced by low-quality references that are generated without laborious tuning and infeasible to deploy by themselves, as long as they can provide a priori knowledge to expedite the learning process.