 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Semantic Segmentation Models for Changes in Illumination and Camera Perspective
Paper and Code
Sep 13, 2018


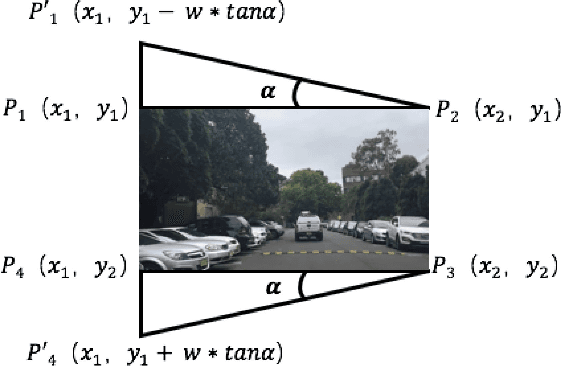
Semantic segmentation using deep neural networks has been widely explored to generate high-level contextual information for autonomous vehicles. To acquire a complete $180^\circ$ semantic understanding of the forward surroundings, we propose to stitch semantic images from multiple cameras with varying orientations. However, previously trained semantic segmentation models showed unacceptable performance after significant changes to the camera orientations and the lighting conditions. To avoid time-consuming hand labeling, we explore and evaluate the use of data augmentation techniques, specifically skew and gamma correction, from a practical real-world standpoint to extend the existing model and provide more robust performance. The presented experimental results have shown significant improvements with varying illumination and camera perspective changes.