 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting an ASR Foundation Model for Spoken Language Assessment
Paper and Code

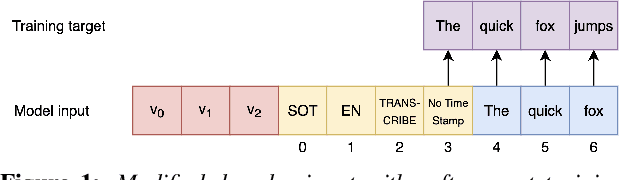


A crucial part of an accurate and reliable spoken language assessment system is the underlying ASR model. Recently, large-scale pre-trained ASR foundation models such as Whisper have been made available. As the output of these models is designed to be human readable, punctuation is added, numbers are presented in Arabic numeric form and abbreviations are included. Additionally, these models have a tendency to skip disfluencies and hesitations in the output. Though useful for readability, these attributes are not helpful for assessing the ability of a candidate and providing feedback. Here a precise transcription of what a candidate said is needed. In this paper, we give a detailed analysis of Whisper outputs and propose two solutions: fine-tuning and soft prompt tuning. Experiments are conducted on both public speech corpora and an English learner dataset. Results show that we can effectively alter the decoding behaviour of Whisper to generate the exact words spoken in the response.