 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-identified Spatiotemporal Action Detection -- Detecting Who Is Doing What in Videos
Paper and Code
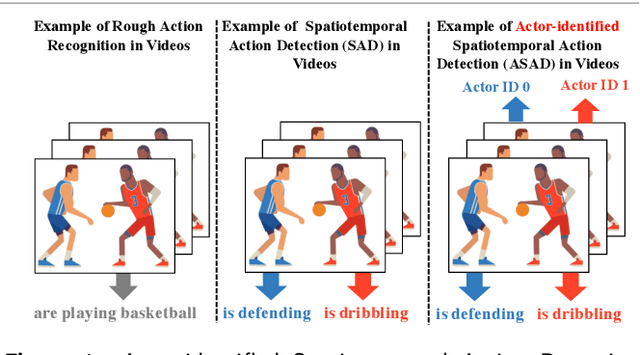



The success of deep learning on video Action Recognition (AR) has motivated researchers to progressively promote related tasks from the coarse level to the fine-grained level. Compared with conventional AR that only predicts an action label for the entire video, Temporal Action Detection (TAD) has been investigated for estimating the start and end time for each action in videos. Taking TAD a step further, Spatiotemporal Action Detection (SAD) has been studied for localizing the action both spatially and temporally in videos. However, who performs the action, is generally ignored in SAD, while identifying the actor could also be important. To this end, we propose a novel task, Actor-identified Spatiotemporal Action Detection (ASAD), to bridge the gap between SAD and actor identification. In ASAD, we not only detect the spatiotemporal boundary for instance-level action but also assign the unique ID to each actor. To approach ASAD, Multiple Object Tracking (MOT) and Action Classification (AC) are two fundamental elements. By using MOT, the spatiotemporal boundary of each actor is obtained and assigned to a unique actor identity. By using AC, the action class is estimated within the corresponding spatiotemporal boundary. Since ASAD is a new task, it poses many new challenges that cannot be addressed by existing methods: i) no dataset is specifically created for ASAD, ii) no evaluation metrics are designed for ASAD, iii) current MOT performance is the bottleneck to obtain satisfactory ASAD results. To address those problems, we contribute to i) annotate a new ASAD dataset, ii) propose ASAD evaluation metrics by considering multi-label actions and actor identification, iii) improve the data association strategies in MOT to boost the MOT performance, which leads to better ASAD results. The code is available at \url{https://github.com/fandulu/ASAD}.