Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Labeling: Streaming Stochastic Gradients
Paper and Code
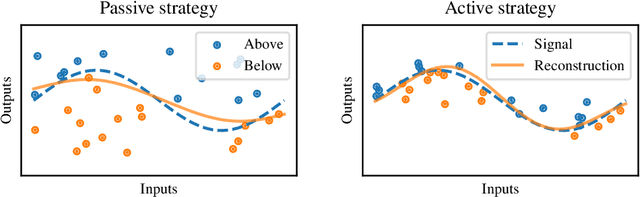
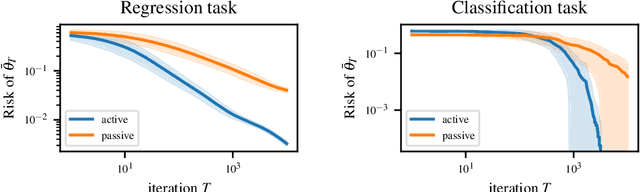
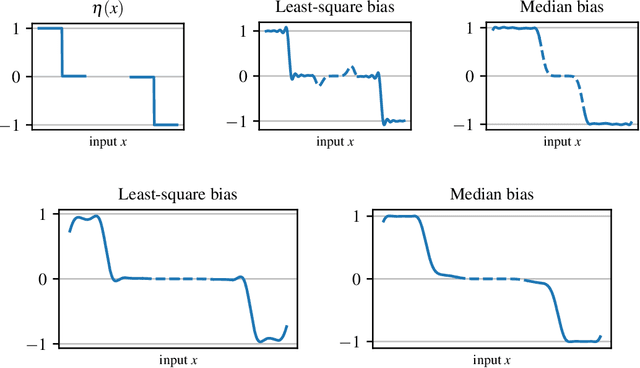
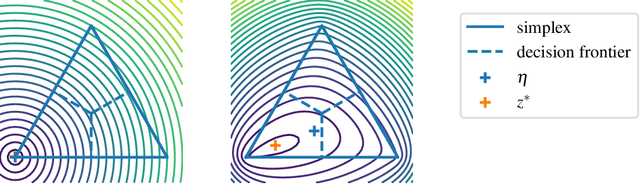
The workhorse of machine learning is stochastic gradient descent. To access stochastic gradients, it is common to consider iteratively input/output pairs of a training dataset. Interestingly, it appears that one does not need full supervision to access stochastic gradients, which is the main motivation of this paper. After formalizing the "active labeling" problem, which generalizes active learning based on partial supervision, we provide a streaming technique that provably minimizes the ratio of generalization error over number of samples. We illustrate our technique in depth for robust regression.
* 38 pages (9 main pages), 9 figures
View paper on
 OpenReview
OpenReview