 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion Models with Parallel Sampling: Inference at Sub-Linear Time Complexity
Paper and Code
May 24, 2024
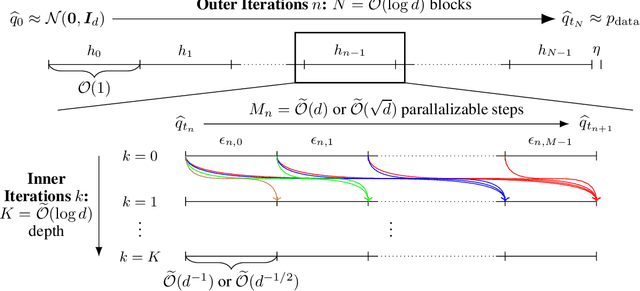

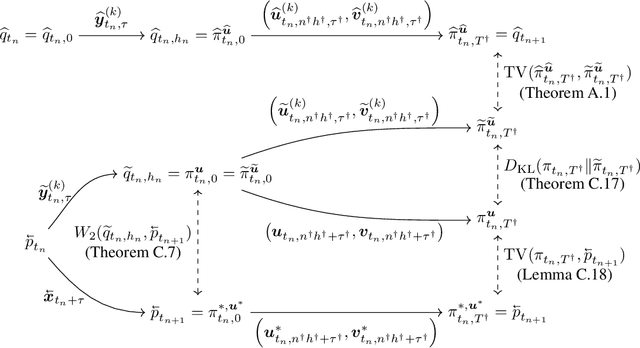
Diffusion models have become a leading method for generative modeling of both image and scientific data. As these models are costly to train and evaluate, reducing the inference cost for diffusion models remains a major goal. Inspired by the recent empirical success in accelerating diffusion models via the parallel sampling technique~\cite{shih2024parallel}, we propose to divide the sampling process into $\mathcal{O}(1)$ blocks with parallelizable Picard iterations within each block. Rigorous theoretical analysis reveals that our algorithm achieves $\widetilde{\mathcal{O}}(\mathrm{poly} \log d)$ overall time complexity, marking the first implementation with provable sub-linear complexity w.r.t. the data dimension $d$. Our analysis is based on a generalized version of Girsanov's theorem and is compatible with both the SDE and probability flow ODE implementations. Our results shed light on the potential of fast and efficient sampling of high-dimensional data on fast-evolving modern large-memory GPU clusters.