Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA3T: Adversarially Augmented Adversarial Training
Paper and Code
Jan 12, 2018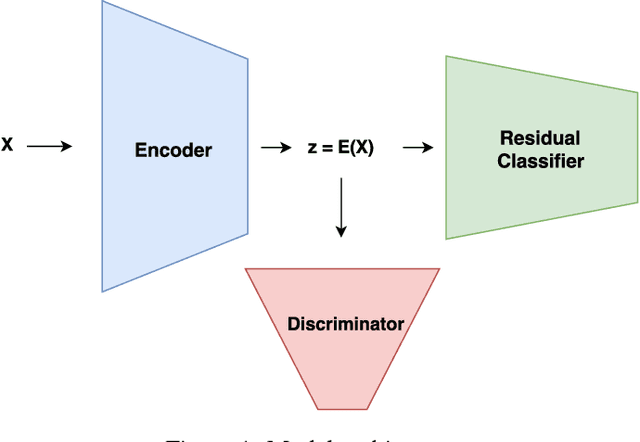

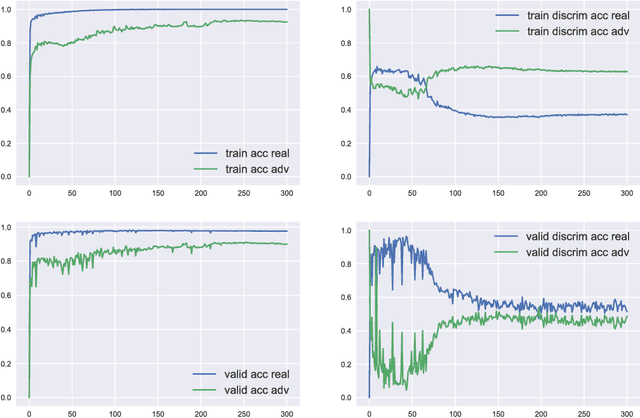
Recent research showed that deep neural networks are highly sensitive to so-called adversarial perturbations, which are tiny perturbations of the input data purposely designed to fool a machine learning classifier. Most classification models, including deep learning models, are highly vulnerable to adversarial attacks. In this work, we investigate a procedure to improve adversarial robustness of deep neural networks through enforcing representation invariance. The idea is to train the classifier jointly with a discriminator attached to one of its hidden layer and trained to filter the adversarial noise. We perform preliminary experiments to test the viability of the approach and to compare it to other standard adversarial training methods.
* accepted for an oral presentation in Machine Deception Workshop, NIPS
2017
View paper on