 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Volumetric Transformer for Accurate 3D Tumor Segmentation
Paper and Code
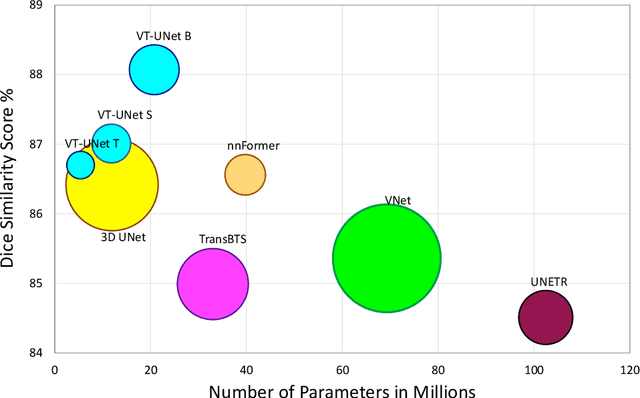
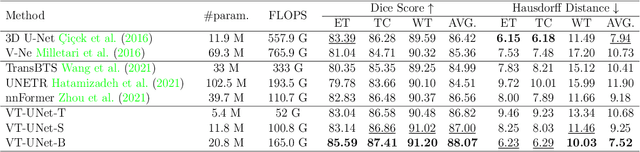
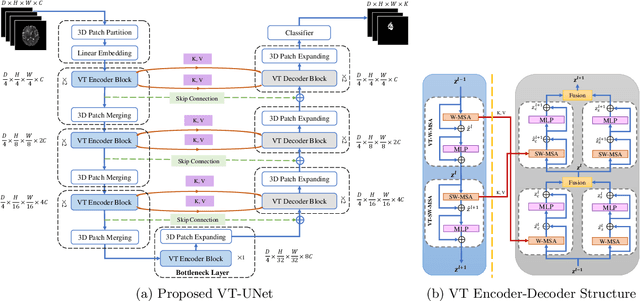
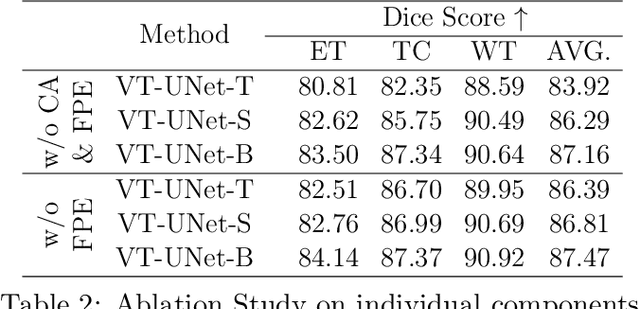
This paper presents a Transformer architecture for volumetric medical image segmentation. Designing a computationally efficient Transformer architecture for volumetric segmentation is a challenging task. It requires keeping a complex balance in encoding local and global spatial cues, and preserving information along all axes of the volumetric data. The proposed volumetric Transformer has a U-shaped encoder-decoder design that processes the input voxels in their entirety. Our encoder has two consecutive self-attention layers to simultaneously encode local and global cues, and our decoder has novel parallel shifted window based self and cross attention blocks to capture fine details for boundary refinement by subsuming Fourier position encoding. Our proposed design choices result in a computationally efficient architecture, which demonstrates promising results on Brain Tumor Segmentation (BraTS) 2021, and Medical Segmentation Decathlon (Pancreas and Liver) datasets for tumor segmentation. We further show that the representations learned by our model transfer better across-datasets and are robust against data corruptions. \href{https://github.com/himashi92/VT-UNet}{Our code implementation is publicly available}.