 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA unified sequence-to-sequence front-end model for Mandarin text-to-speech synthesis
Paper and Code
Nov 11, 2019

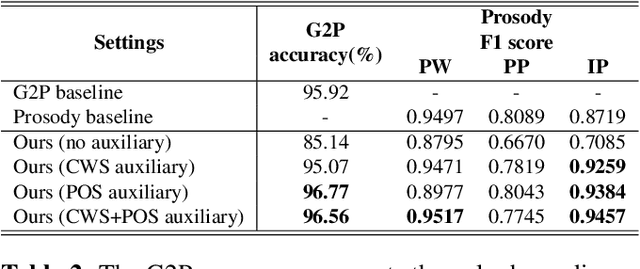
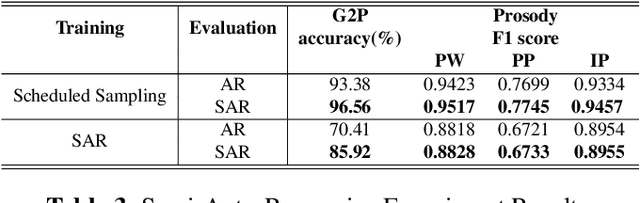
In Mandarin text-to-speech (TTS) system, the front-end text processing module significantly influences the intelligibility and naturalness of synthesized speech. Building a typical pipeline-based front-end which consists of multiple individual components requires extensive efforts. In this paper, we proposed a unified sequence-to-sequence front-end model for Mandarin TTS that converts raw texts to linguistic features directly. Compared to the pipeline-based front-end, our unified front-end can achieve comparable performance in polyphone disambiguation and prosody word prediction, and improve intonation phrase prediction by 0.0738 in F1 score. We also implemented the unified front-end with Tacotron and WaveRNN to build a Mandarin TTS system. The synthesized speech by that got a comparable MOS (4.38) with the pipeline-based front-end (4.37) and close to human recordings (4.49).