 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework to Enforce, Discover, and Promote Symmetry in Machine Learning
Paper and Code
Nov 01, 2023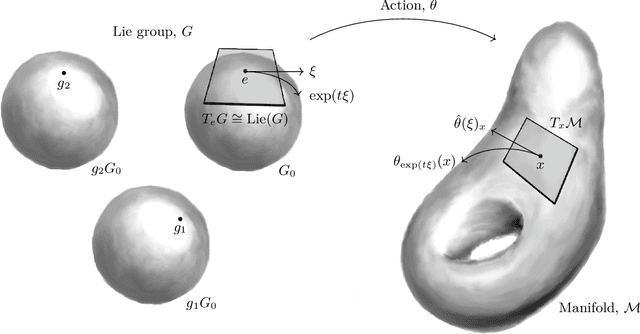
Symmetry is present throughout nature and continues to play an increasingly central role in physics and machine learning. Fundamental symmetries, such as Poincar\'{e} invariance, allow physical laws discovered in laboratories on Earth to be extrapolated to the farthest reaches of the universe. Symmetry is essential to achieving this extrapolatory power in machine learning applications. For example, translation invariance in image classification allows models with fewer parameters, such as convolutional neural networks, to be trained on smaller data sets and achieve state-of-the-art performance. In this paper, we provide a unifying theoretical and methodological framework for incorporating symmetry into machine learning models in three ways: 1. enforcing known symmetry when training a model; 2. discovering unknown symmetries of a given model or data set; and 3. promoting symmetry during training by learning a model that breaks symmetries within a user-specified group of candidates when there is sufficient evidence in the data. We show that these tasks can be cast within a common mathematical framework whose central object is the Lie derivative associated with fiber-linear Lie group actions on vector bundles. We extend and unify several existing results by showing that enforcing and discovering symmetry are linear-algebraic tasks that are dual with respect to the bilinear structure of the Lie derivative. We also propose a novel way to promote symmetry by introducing a class of convex regularization functions based on the Lie derivative and nuclear norm relaxation to penalize symmetry breaking during training of machine learning models. We explain how these ideas can be applied to a wide range of machine learning models including basis function regression, dynamical systems discovery, multilayer perceptrons, and neural networks acting on spatial fields such as images.