 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Approach to Controlling Implicit Regularization via Mirror Descent
Paper and Code
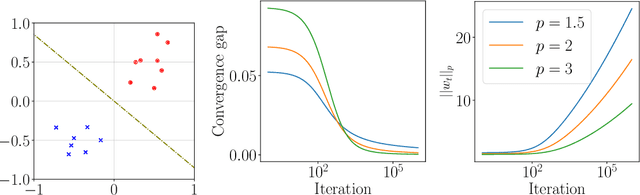
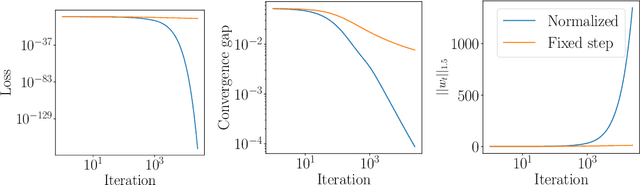
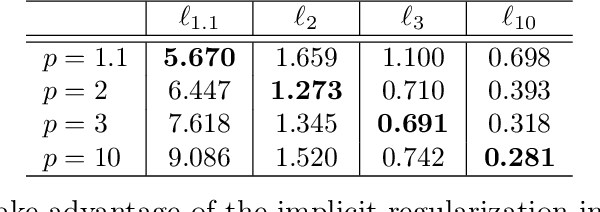
Inspired by the remarkable success of deep neural networks, there has been significant interest in understanding the generalization performance of overparameterized models. Substantial efforts have been invested in characterizing how optimization algorithms impact generalization through their "preferred" solutions, a phenomenon commonly referred to as implicit regularization. In particular, it has been argued that gradient descent (GD) induces an implicit $\ell_2$-norm regularization in regression and classification problems. However, the implicit regularization of different algorithms are confined to either a specific geometry or a particular class of learning problems, indicating a gap in a general approach for controlling the implicit regularization. To address this, we present a unified approach using mirror descent (MD), a notable generalization of GD, to control implicit regularization in both regression and classification settings. More specifically, we show that MD with the general class of homogeneous potential functions converges in direction to a generalized maximum-margin solution for linear classification problems, thereby answering a long-standing question in the classification setting. Further, we show that MD can be implemented efficiently and under suitable conditions, enjoys fast convergence. Through comprehensive experiments, we demonstrate that MD is a versatile method to produce learned models with different regularizers, which in turn have different generalization performances.