 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Analysis of the Repetition Problem in Text Generation
Paper and Code

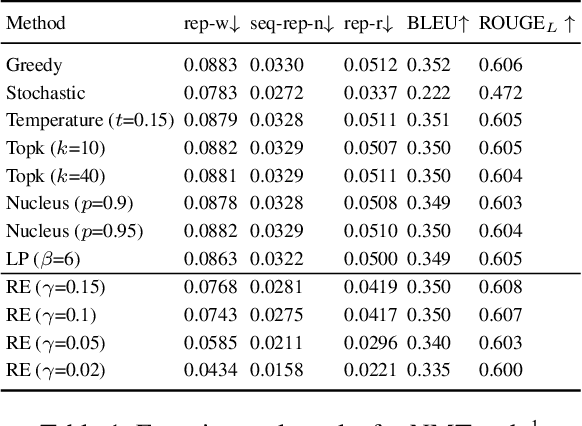


Text generation tasks, including translation, summarization, language models, and etc. see rapid growth during recent years. Despite the remarkable achievements, the repetition problem has been observed in nearly all text generation models undermining the generation performance extensively. To solve the repetition problem, many methods have been proposed, but there is no existing theoretical analysis to show why this problem happens and how it is resolved. In this paper, we propose a new framework for theoretical analysis for the repetition problem. We first define the Average Repetition Probability (ARP) to characterize the repetition problem quantitatively. Then, we conduct an extensive analysis of the Markov generation model and derive several upper bounds of the average repetition probability with intuitive understanding. We show that most of the existing methods are essentially minimizing the upper bounds explicitly or implicitly. Grounded on our theory, we show that the repetition problem is, unfortunately, caused by the traits of our language itself. One major reason is attributed to the fact that there exist too many words predicting the same word as the subsequent word with high probability. Consequently, it is easy to go back to that word and form repetitions and we dub it as the high inflow problem. Furthermore, we derive a concentration bound of the average repetition probability for a general generation model. Finally, based on the theoretical upper bounds, we propose a novel rebalanced encoding approach to alleviate the high inflow problem. The experimental results show that our theoretical framework is applicable in general generation models and our proposed rebalanced encoding approach alleviates the repetition problem significantly. The source code of this paper can be obtained from \url{https://github.com/fuzihaofzh/repetition-problem-nlg}.