 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Large-scale Machine Learning
Paper and Code
Aug 10, 2020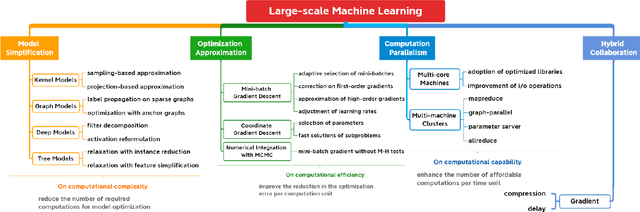


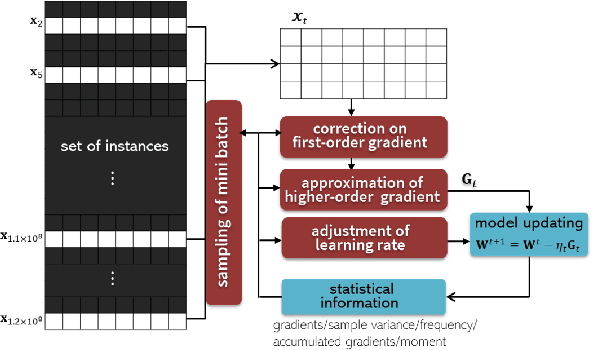
Machine learning can provide deep insights into data, allowing machines to make high-quality predictions and having been widely used in real-world applications, such as text mining, visual classification, and recommender systems. However, most sophisticated machine learning approaches suffer from huge time costs when operating on large-scale data. This issue calls for the need of {Large-scale Machine Learning} (LML), which aims to learn patterns from big data with comparable performance efficiently. In this paper, we offer a systematic survey on existing LML methods to provide a blueprint for the future developments of this area. We first divide these LML methods according to the ways of improving the scalability: 1) model simplification on computational complexities, 2) optimization approximation on computational efficiency, and 3) computation parallelism on computational capabilities. Then we categorize the methods in each perspective according to their targeted scenarios and introduce representative methods in line with intrinsic strategies. Lastly, we analyze their limitations and discuss potential directions as well as open issues that are promising to address in the future.