 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatial-Temporal Attentive Network with Spatial Continuity for Trajectory Prediction
Paper and Code
Mar 16, 2020
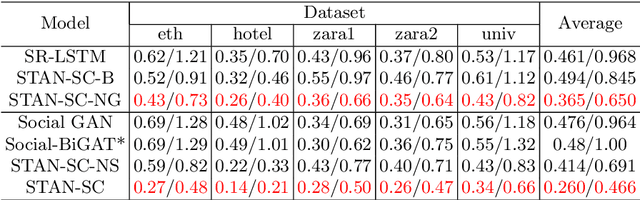
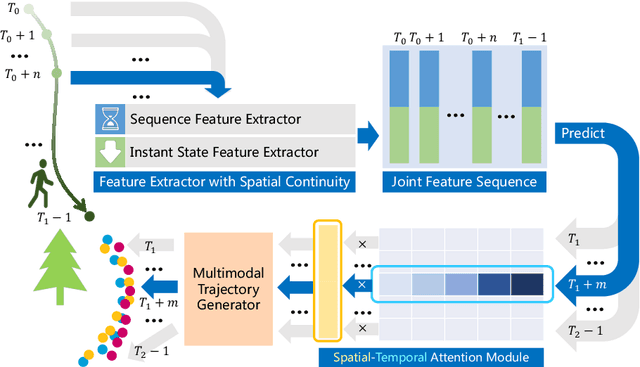
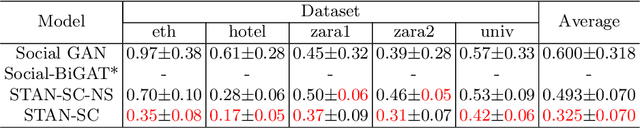
It remains challenging to automatically predict the multi-agent trajectory due to multiple interactions including agent to agent interaction and scene to agent interaction. Although recent methods have achieved promising performance, most of them just consider spatial influence of the interactions and ignore the fact that temporal influence always accompanies spatial influence. Moreover, those methods based on scene information always require extra segmented scene images to generate multiple socially acceptable trajectories. To solve these limitations, we propose a novel model named spatial-temporal attentive network with spatial continuity (STAN-SC). First, spatial-temporal attention mechanism is presented to explore the most useful and important information. Second, we conduct a joint feature sequence based on the sequence and instant state information to make the generative trajectories keep spatial continuity. Experiments are performed on the two widely used ETH-UCY datasets and demonstrate that the proposed model achieves state-of-the-art prediction accuracy and handles more complex scenarios.