 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simulation Platform for Multi-tenant Machine Learning Services on Thousands of GPUs
Paper and Code
Jan 10, 2022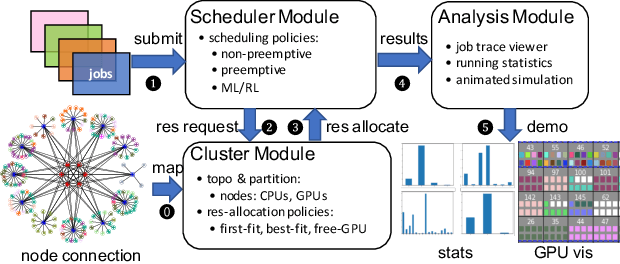


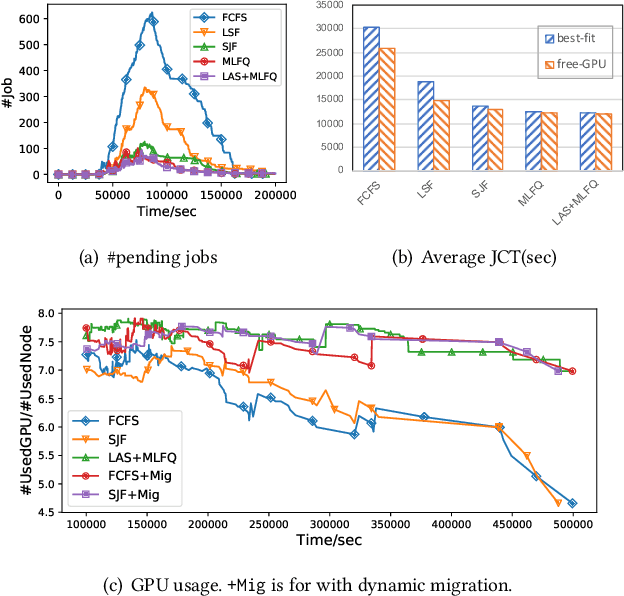
Multi-tenant machine learning services have become emerging data-intensive workloads in data centers with heavy usage of GPU resources. Due to the large scale, many tuning parameters and heavy resource usage, it is usually impractical to evaluate and benchmark those machine learning services on real clusters. In this demonstration, we present AnalySIM, a cluster simulator that allows efficient design explorations for multi-tenant machine learning services. Specifically, by trace-driven cluster workload simulation, AnalySIM can easily test and analyze various scheduling policies in a number of performance metrics such as GPU resource utilization. AnalySIM simulates the cluster computational resource based on both physical topology and logical partition. The tool has been used in SenseTime to understand the impact of different scheduling policies with the trace from a real production cluster of over 1000 GPUs. We find that preemption and migration are able to significantly reduce average job completion time and mitigate the resource fragmentation problem.