 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Data Mixing Prior for Improving Self-Supervised Learning
Paper and Code

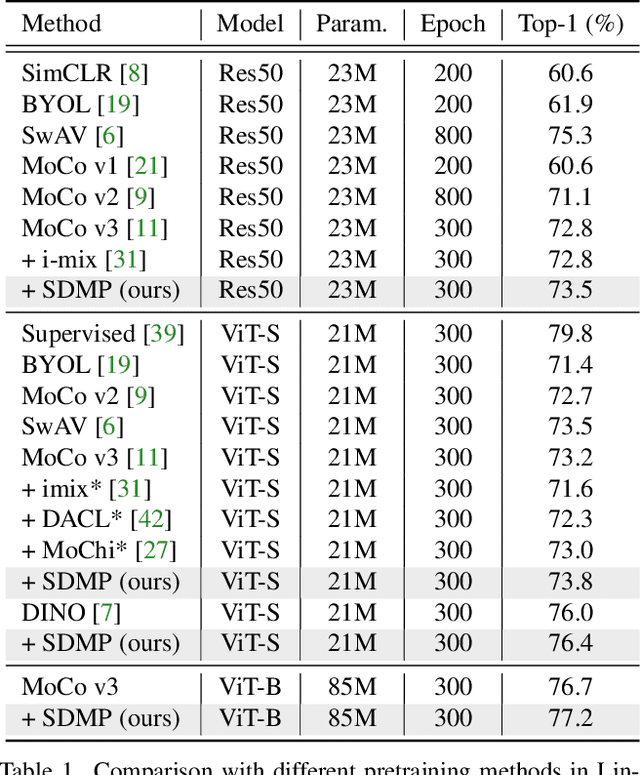

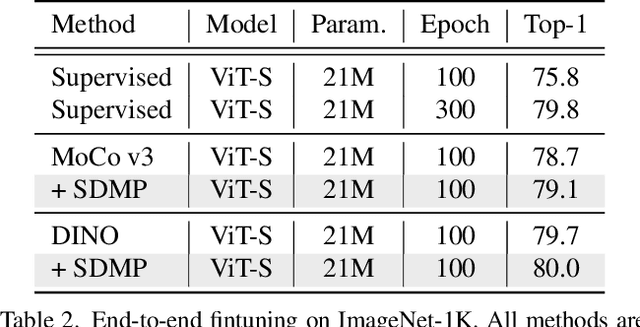
Data mixing (e.g., Mixup, Cutmix, ResizeMix) is an essential component for advancing recognition models. In this paper, we focus on studying its effectiveness in the self-supervised setting. By noticing the mixed images that share the same source images are intrinsically related to each other, we hereby propose SDMP, short for $\textbf{S}$imple $\textbf{D}$ata $\textbf{M}$ixing $\textbf{P}$rior, to capture this straightforward yet essential prior, and position such mixed images as additional $\textbf{positive pairs}$ to facilitate self-supervised representation learning. Our experiments verify that the proposed SDMP enables data mixing to help a set of self-supervised learning frameworks (e.g., MoCo) achieve better accuracy and out-of-distribution robustness. More notably, our SDMP is the first method that successfully leverages data mixing to improve (rather than hurt) the performance of Vision Transformers in the self-supervised setting. Code is publicly available at https://github.com/OliverRensu/SDMP