 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Workflow to Build Machine Learning Classifiers with Clinician-in-the-Loop to Identify Patients in Specific Diseases
Paper and Code
May 18, 2022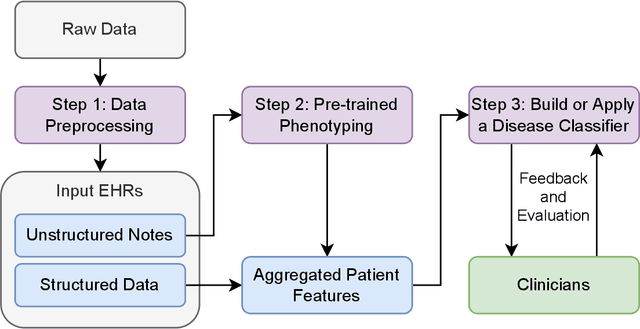

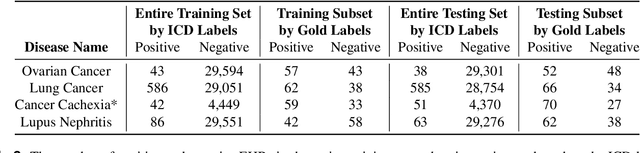
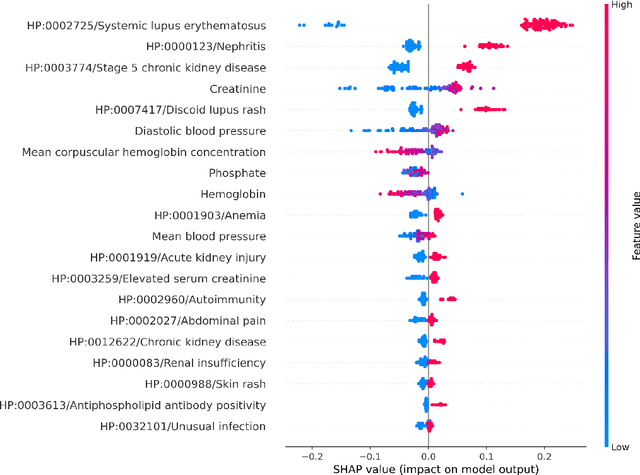
Clinicians may rely on medical coding systems such as International Classification of Diseases (ICD) to identify patients with diseases from Electronic Health Records (EHRs). However, due to the lack of detail and specificity as well as a probability of miscoding, recent studies suggest the ICD codes often cannot characterise patients accurately for specific diseases in real clinical practice, and as a result, using them to find patients for studies or trials can result in high failure rates and missing out on uncoded patients. Manual inspection of all patients at scale is not feasible as it is highly costly and slow. This paper proposes a scalable workflow which leverages both structured data and unstructured textual notes from EHRs with techniques including NLP, AutoML and Clinician-in-the-Loop mechanism to build machine learning classifiers to identify patients at scale with given diseases, especially those who might currently be miscoded or missed by ICD codes. Case studies in the MIMIC-III dataset were conducted where the proposed workflow demonstrates a higher classification performance in terms of F1 scores compared to simply using ICD codes on gold testing subset to identify patients with Ovarian Cancer (0.901 vs 0.814), Lung Cancer (0.859 vs 0.828), Cancer Cachexia (0.862 vs 0.650), and Lupus Nephritis (0.959 vs 0.855). Also, the proposed workflow that leverages unstructured notes consistently outperforms the baseline that uses structured data only with an increase of F1 (Ovarian Cancer 0.901 vs 0.719, Lung Cancer 0.859 vs 0.787, Cancer Cachexia 0.862 vs 0.838 and Lupus Nephritis 0.959 vs 0.785). Experiments on the large testing set also demonstrate the proposed workflow can find more patients who are miscoded or missed by ICD codes. Moreover, interpretability studies are also conducted to clinically validate the top impact features of the classifiers.