 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Graph-Theoretic Distributed Framework for Cooperative Multi-Agent Reinforcement Learning
Paper and Code
Mar 01, 2022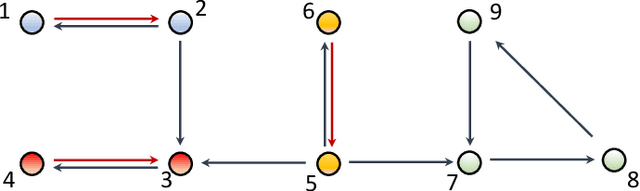
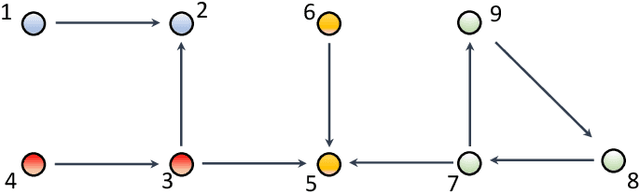
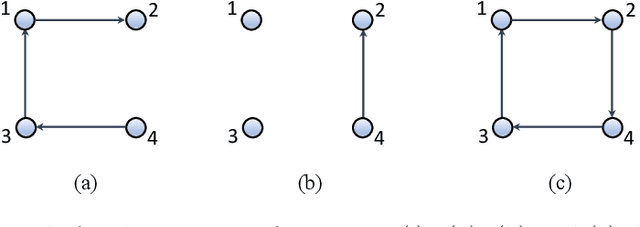
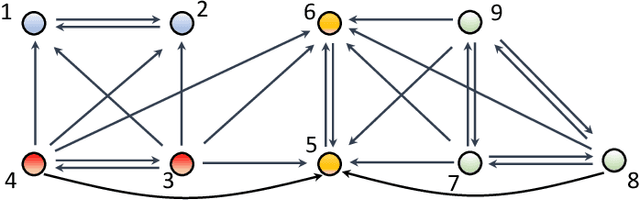
The main challenge of large-scale cooperative multi-agent reinforcement learning (MARL) is two-fold: (i) the RL algorithm is desired to be distributed due to limited resource for each individual agent; (ii) issues on convergence or computational complexity emerge due to the curse of dimensionality. Unfortunately, most of existing distributed RL references only focus on ensuring that the individual policy-seeking process of each agent is based on local information, but fail to solve the scalability issue induced by high dimensions of the state and action spaces when facing large-scale networks. In this paper, we propose a general distributed framework for cooperative MARL by utilizing the structures of graphs involved in this problem. We introduce three graphs in MARL, namely, the coordination graph, the observation graph and the reward graph. Based on these three graphs, and a given communication graph, we propose two distributed RL approaches. The first approach utilizes the inherent decomposability property of the problem itself, whose efficiency depends on the structures of the aforementioned four graphs, and is able to produce a high performance under specific graphical conditions. The second approach provides an approximate solution and is applicable for any graphs. Here the approximation error depends on an artificially designed index. The choice of this index is a trade-off between minimizing the approximation error and reducing the computational complexity. Simulations show that our RL algorithms have a significantly improved scalability to large-scale MASs compared with centralized and consensus-based distributed RL algorithms.