 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA roadmap to fair and trustworthy prediction model validation in healthcare
Paper and Code
Apr 07, 2023
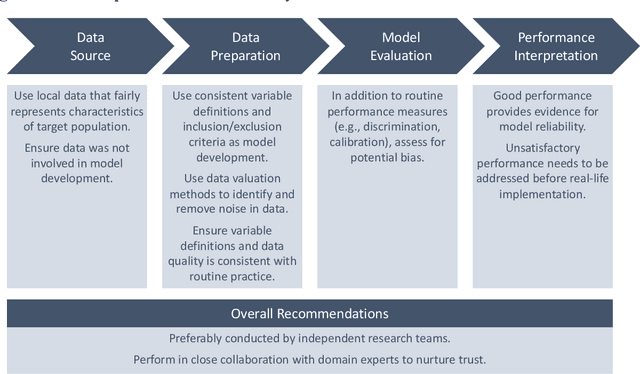
A prediction model is most useful if it generalizes beyond the development data with external validations, but to what extent should it generalize remains unclear. In practice, prediction models are externally validated using data from very different settings, including populations from other health systems or countries, with predictably poor results. This may not be a fair reflection of the performance of the model which was designed for a specific target population or setting, and may be stretching the expected model generalizability. To address this, we suggest to externally validate a model using new data from the target population to ensure clear implications of validation performance on model reliability, whereas model generalizability to broader settings should be carefully investigated during model development instead of explored post-hoc. Based on this perspective, we propose a roadmap that facilitates the development and application of reliable, fair, and trustworthy artificial intelligence prediction models.