Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Rank-Based Similarity Metric for Word Embeddings
Paper and Code
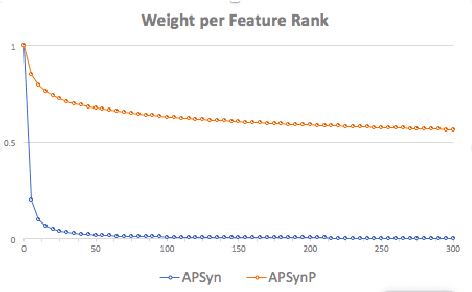

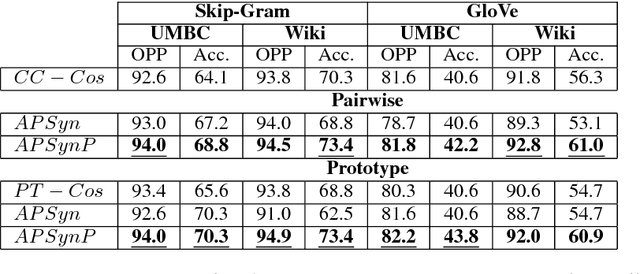
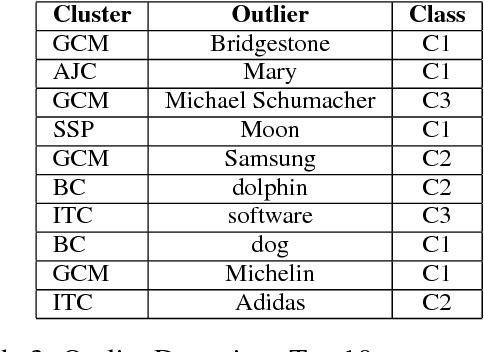
Word Embeddings have recently imposed themselves as a standard for representing word meaning in NLP. Semantic similarity between word pairs has become the most common evaluation benchmark for these representations, with vector cosine being typically used as the only similarity metric. In this paper, we report experiments with a rank-based metric for WE, which performs comparably to vector cosine in similarity estimation and outperforms it in the recently-introduced and challenging task of outlier detection, thus suggesting that rank-based measures can improve clustering quality.
* 5 pages, 1 figure, 4 tables, ACL, ACL2018
View paper on