 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA principled approach for generating adversarial images under non-smooth dissimilarity metrics
Paper and Code
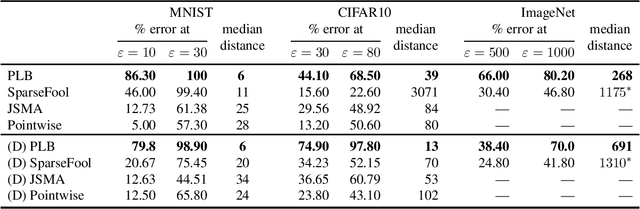


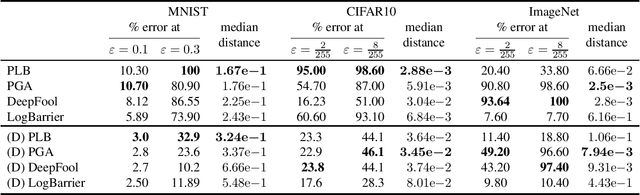
Deep neural networks are vulnerable to adversarial perturbations: small changes in the input easily lead to misclassification. In this work, we propose an attack methodology catered not only for cases where the perturbations are measured by $\ell_p$ norms, but in fact any adversarial dissimilarity metric with a closed proximal form. This includes, but is not limited to, $\ell_1$, $\ell_2$, $\ell_\infty$ perturbations, and the $\ell_0$ counting "norm", i.e. true sparseness. Our approach to generating perturbations is a natural extension of our recent work, the LogBarrier attack, which previously required the metric to be differentiable. We demonstrate our new algorithm, ProxLogBarrier, on the MNIST, CIFAR10, and ImageNet-1k datasets. We attack undefended and defended models, and show that our algorithm transfers to various datasets with little parameter tuning. In particular, in the $\ell_0$ case, our algorithm finds significantly smaller perturbations compared to multiple existing methods