 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Notion of Individually Fair Clustering: $α$-Equitable $k$-Center
Paper and Code

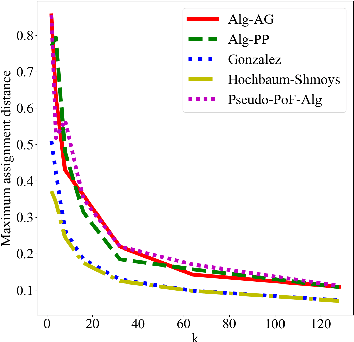
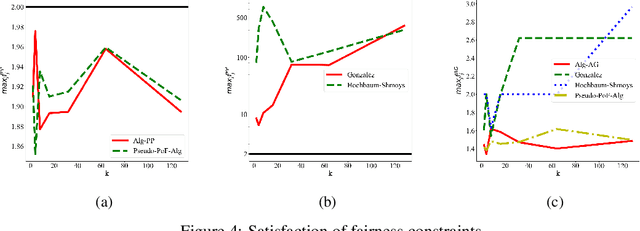
Clustering is a fundamental problem in unsupervised machine learning, and fair variants of it have recently received significant attention. In this work we introduce a novel definition of fairness for clustering problems. Specifically, in our model each point $j$ has a set of other points $\mathcal{S}_j$ that it perceives as similar to itself, and it feels that it is fairly treated, if the quality of service it receives in the solution is $\alpha$-close to that of the points in $\mathcal{S}_j$. We begin our study by answering questions regarding the structure of the problem, namely for what values of $\alpha$ the problem is well-defined, and what the behavior of the Price of Fairness (PoF) for it is. For the well-defined region of $\alpha$, we provide efficient and easily implementable approximation algorithms for the $k$-center objective, which in certain cases also enjoy bounded PoF guarantees. We finally complement our analysis by an extensive suite of experiments that validates the effectiveness of our theoretical results.