 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-scale Transformer for Medical Image Segmentation: Architectures, Model Efficiency, and Benchmarks
Paper and Code
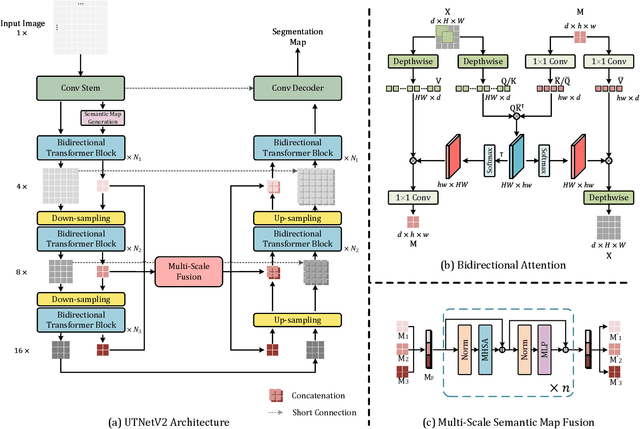
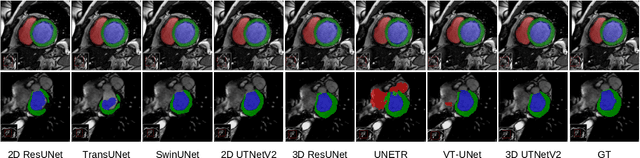
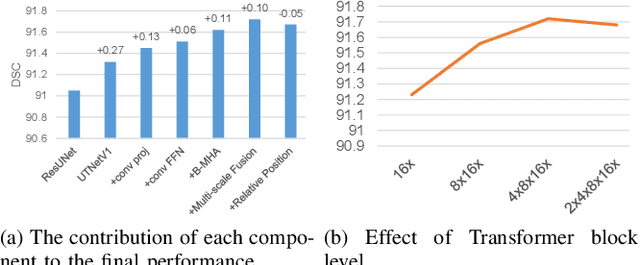
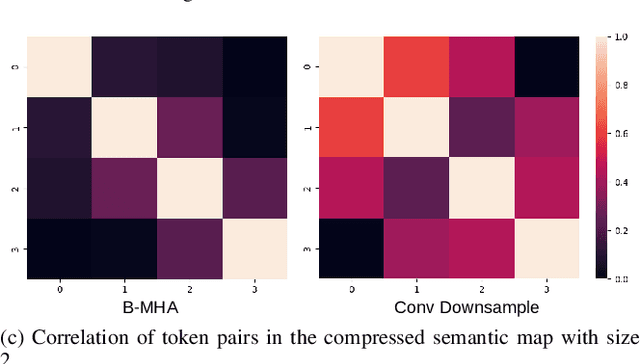
Transformers have emerged to be successful in a number of natural language processing and vision tasks, but their potential applications to medical imaging remain largely unexplored due to the unique difficulties of this field. In this study, we present UTNetV2, a simple yet powerful backbone model that combines the strengths of the convolutional neural network and Transformer for enhancing performance and efficiency in medical image segmentation. The critical design of UTNetV2 includes three innovations: (1) We used a hybrid hierarchical architecture by introducing depthwise separable convolution to projection and feed-forward network in the Transformer block, which brings local relationship modeling and desirable properties of CNNs (translation invariance) to Transformer, thus eliminate the requirement of large-scale pre-training. (2) We proposed efficient bidirectional attention (B-MHA) that reduces the quadratic computation complexity of self-attention to linear by introducing an adaptively updated semantic map. The efficient attention makes it possible to capture long-range relationship and correct the fine-grained errors in high-resolution token maps. (3) The semantic maps in the B-MHA allow us to perform semantically and spatially global multi-scale feature fusion without introducing much computational overhead. Furthermore, we provide a fair comparison codebase of CNN-based and Transformer-based on various medical image segmentation tasks to evaluate the merits and defects of both architectures. UTNetV2 demonstrated state-of-the-art performance across various settings, including large-scale datasets, small-scale datasets, 2D and 3D settings.