 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Approach to Zero-Shot and Few-Shot Action Recognition
Paper and Code
Jan 27, 2018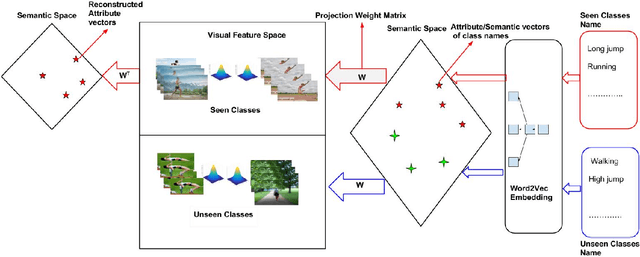

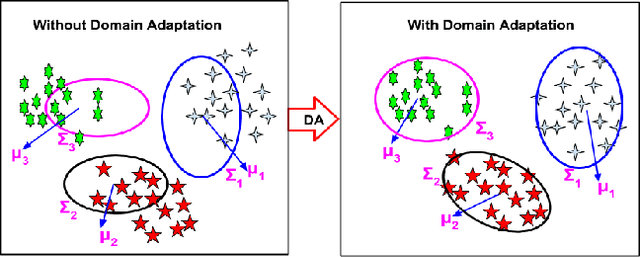
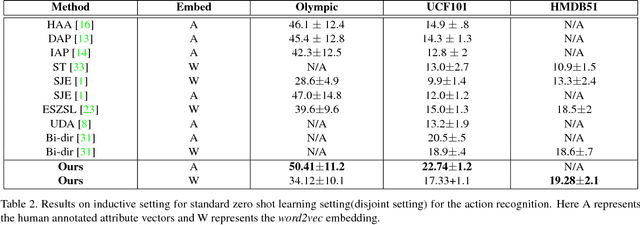
We present a generative framework for zero-shot action recognition where some of the possible action classes do not occur in the training data. Our approach is based on modeling each action class using a probability distribution whose parameters are functions of the attribute vector representing that action class. In particular, we assume that the distribution parameters for any action class in the visual space can be expressed as a linear combination of a set of basis vectors where the combination weights are given by the attributes of the action class. These basis vectors can be learned solely using labeled data from the known (i.e., previously seen) action classes, and can then be used to predict the parameters of the probability distributions of unseen action classes. We consider two settings: (1) Inductive setting, where we use only the labeled examples of the seen action classes to predict the unseen action class parameters; and (2) Transductive setting which further leverages unlabeled data from the unseen action classes. Our framework also naturally extends to few-shot action recognition where a few labeled examples from unseen classes are available. Our experiments on benchmark datasets (UCF101, HMDB51 and Olympic) show significant performance improvements as compared to various baselines, in both standard zero-shot (disjoint seen and unseen classes) and generalized zero-shot learning settings.