 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA CTC Triggered Siamese Network with Spatial-Temporal Dropout for Speech Recognition
Paper and Code
Jun 22, 2022
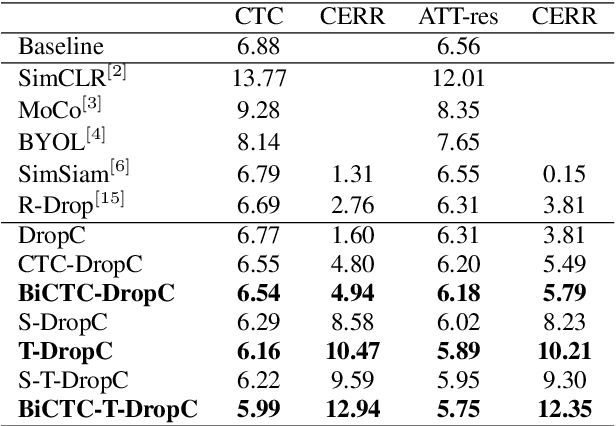
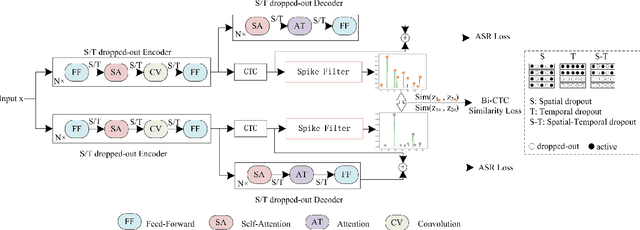
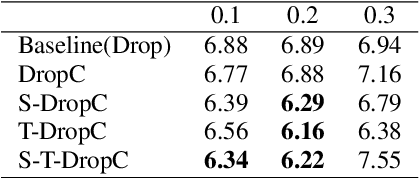
Siamese networks have shown effective results in unsupervised visual representation learning. These models are designed to learn an invariant representation of two augmentations for one input by maximizing their similarity. In this paper, we propose an effective Siamese network to improve the robustness of End-to-End automatic speech recognition (ASR). We introduce spatial-temporal dropout to support a more violent disturbance for Siamese-ASR framework. Besides, we also relax the similarity regularization to maximize the similarities of distributions on the frames that connectionist temporal classification (CTC) spikes occur rather than on all of them. The efficiency of the proposed architecture is evaluated on two benchmarks, AISHELL-1 and Librispeech, resulting in 7.13% and 6.59% relative character error rate (CER) and word error rate (WER) reductions respectively. Analysis shows that our proposed approach brings a better uniformity for the trained model and enlarges the CTC spikes obviously.