 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Understanding of Code-mixed Language Semantics using Hierarchical Transformer
Paper and Code
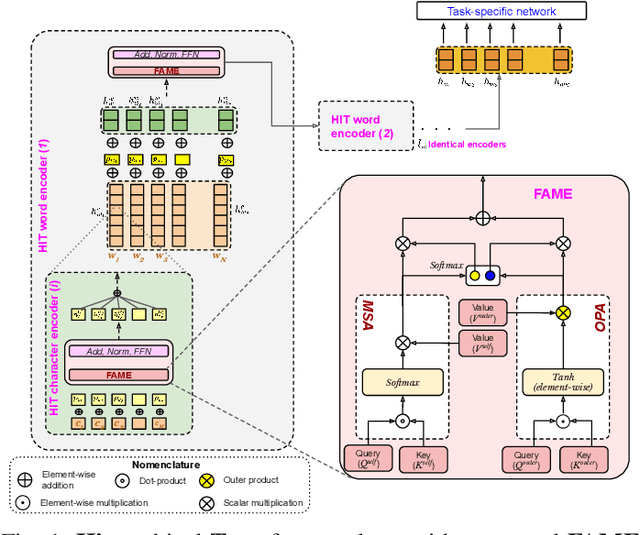
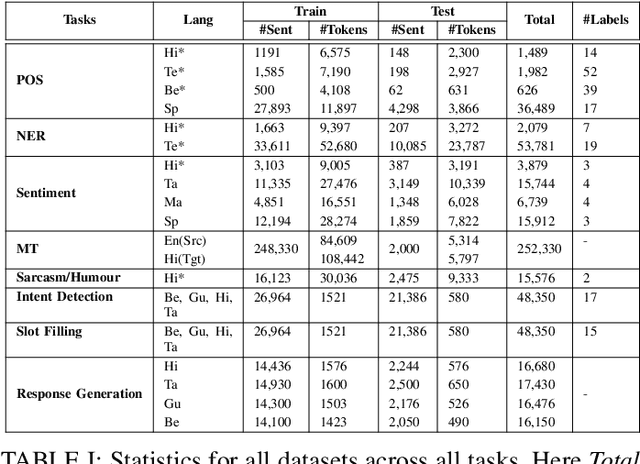

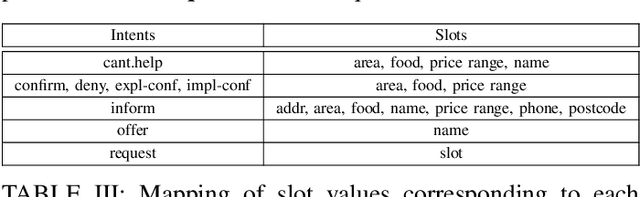
Being a popular mode of text-based communication in multilingual communities, code-mixing in online social media has became an important subject to study. Learning the semantics and morphology of code-mixed language remains a key challenge, due to scarcity of data and unavailability of robust and language-invariant representation learning technique. Any morphologically-rich language can benefit from character, subword, and word-level embeddings, aiding in learning meaningful correlations. In this paper, we explore a hierarchical transformer-based architecture (HIT) to learn the semantics of code-mixed languages. HIT consists of multi-headed self-attention and outer product attention components to simultaneously comprehend the semantic and syntactic structures of code-mixed texts. We evaluate the proposed method across 6 Indian languages (Bengali, Gujarati, Hindi, Tamil, Telugu and Malayalam) and Spanish for 9 NLP tasks on 17 datasets. The HIT model outperforms state-of-the-art code-mixed representation learning and multilingual language models in all tasks. We further demonstrate the generalizability of the HIT architecture using masked language modeling-based pre-training, zero-shot learning, and transfer learning approaches. Our empirical results show that the pre-training objectives significantly improve the performance on downstream tasks.