 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Cross-modal Retrieval
Paper and Code
Jul 21, 2016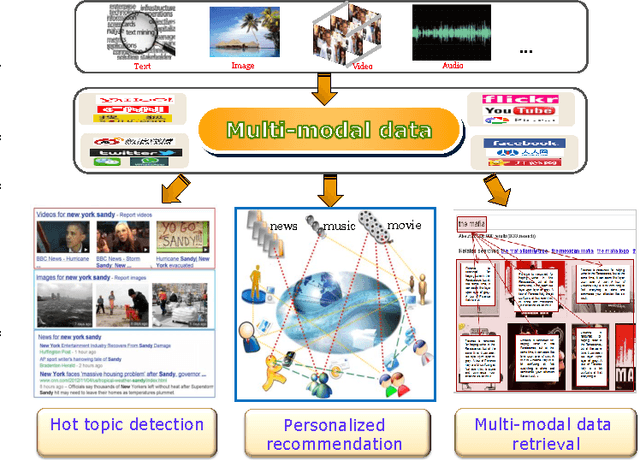
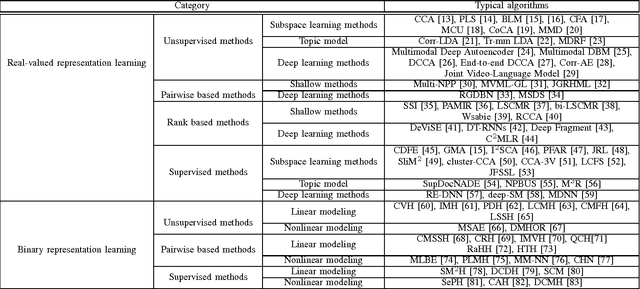


In recent years, cross-modal retrieval has drawn much attention due to the rapid growth of multimodal data. It takes one type of data as the query to retrieve relevant data of another type. For example, a user can use a text to retrieve relevant pictures or videos. Since the query and its retrieved results can be of different modalities, how to measure the content similarity between different modalities of data remains a challenge. Various methods have been proposed to deal with such a problem. In this paper, we first review a number of representative methods for cross-modal retrieval and classify them into two main groups: 1) real-valued representation learning, and 2) binary representation learning. Real-valued representation learning methods aim to learn real-valued common representations for different modalities of data. To speed up the cross-modal retrieval, a number of binary representation learning methods are proposed to map different modalities of data into a common Hamming space. Then, we introduce several multimodal datasets in the community, and show the experimental results on two commonly used multimodal datasets. The comparison reveals the characteristic of different kinds of cross-modal retrieval methods, which is expected to benefit both practical applications and future research. Finally, we discuss open problems and future research directions.