 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Analysis of AI Biases in DeepFake Detection With Massively Annotated Databases
Paper and Code
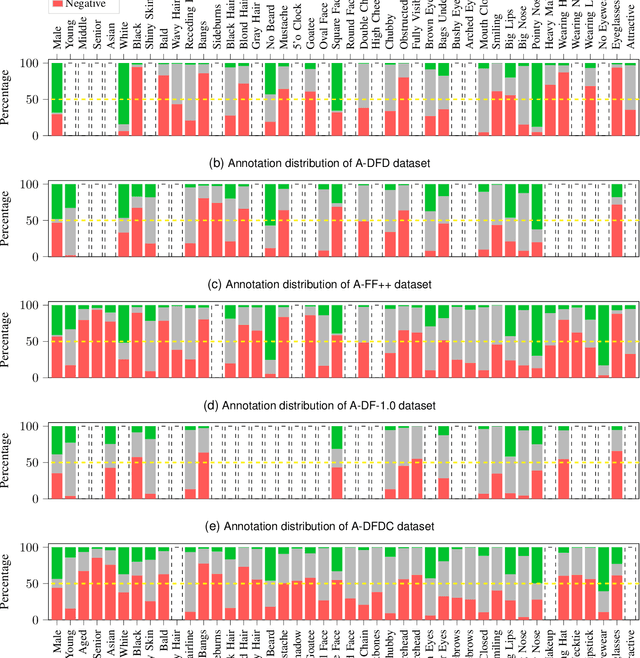

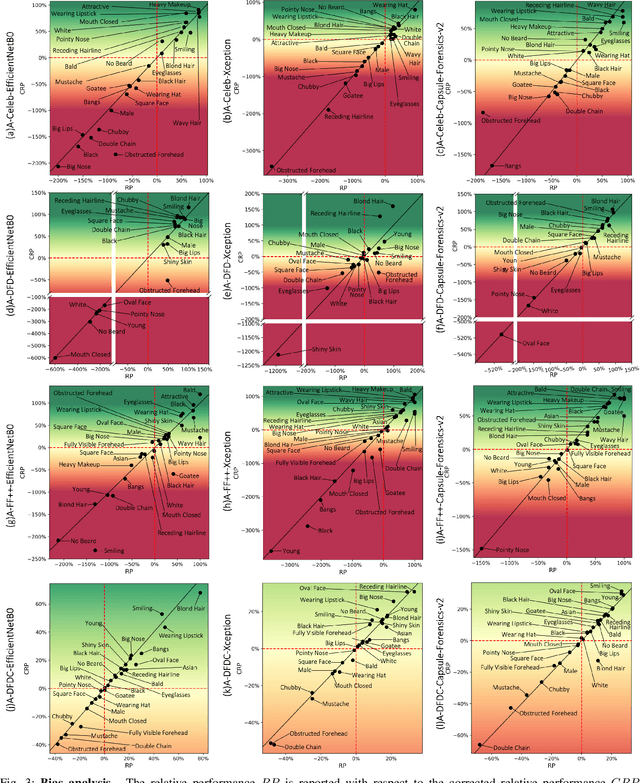

In recent years, image and video manipulations with DeepFake have become a severe concern for security and society. Therefore, many detection models and databases have been proposed to detect DeepFake data reliably. However, there is an increased concern that these models and training databases might be biased and thus, cause DeepFake detectors to fail. In this work, we tackle these issues by (a) providing large-scale demographic and non-demographic attribute annotations of 41 different attributes for five popular DeepFake datasets and (b) comprehensively analysing AI-bias of multiple state-of-the-art DeepFake detection models on these databases. The investigation analyses the influence of a large variety of distinctive attributes (from over 65M labels) on the detection performance, including demographic (age, gender, ethnicity) and non-demographic (hair, skin, accessories, etc.) information. The results indicate that investigated databases lack diversity and, more importantly, show that the utilised DeepFake detection models are strongly biased towards many investigated attributes. Moreover, the results show that the models' decision-making might be based on several questionable (biased) assumptions, such if a person is smiling or wearing a hat. Depending on the application of such DeepFake detection methods, these biases can lead to generalizability, fairness, and security issues. We hope that the findings of this study and the annotation databases will help to evaluate and mitigate bias in future DeepFake detection techniques. Our annotation datasets are made publicly available.