 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Measurement Study of Deep Learning as a Service Framework
Paper and Code
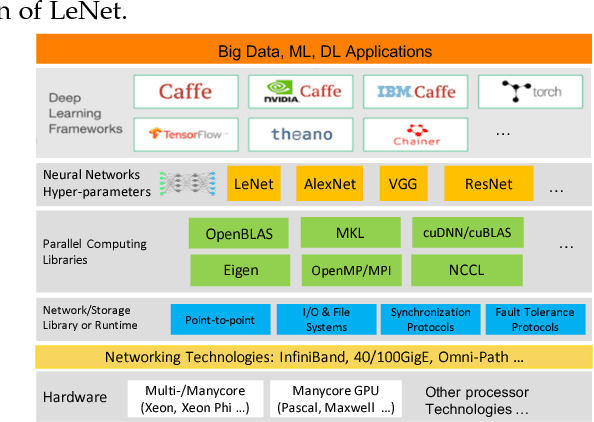
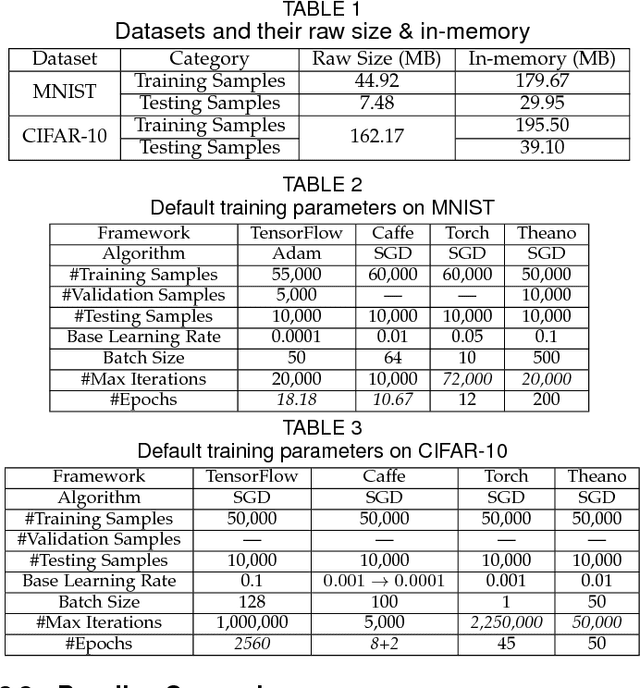
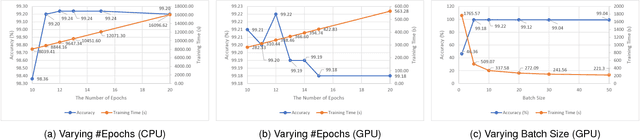
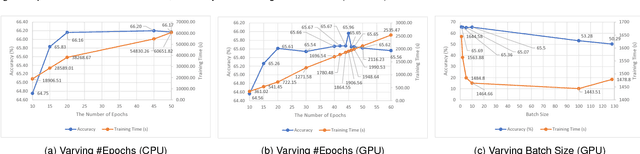
Big data powered Deep Learning (DL) and its applications have blossomed in recent years, fueled by three technological trends: a large amount of digitized data openly accessible, a growing number of DL software frameworks in open source and commercial markets, and a selection of affordable parallel computing hardware devices. However, no single DL framework, to date, dominates in terms of performance and accuracy even for baseline classification tasks on standard datasets, making the selection of a DL framework an overwhelming task. This paper takes a holistic approach to conduct empirical comparison and analysis of four representative DL frameworks with three unique contributions. First, given a selection of CPU-GPU configurations, we show that for a specific DL framework, different configurations of its hyper-parameters may have significant impact on both performance and accuracy of DL applications. Second, the optimal configuration of hyper-parameters for one DL framework (e.g., TensorFlow) often does not work well for another DL framework (e.g., Caffe or Torch) under the same CPU-GPU runtime environment. Third, we also conduct a comparative measurement study on the resource consumption patterns of four DL frameworks and their performance and accuracy implications, including CPU and memory usage, and their correlations to varying settings of hyper-parameters under different configuration combinations of hardware, parallel computing libraries. We argue that this measurement study provides in-depth empirical comparison and analysis of four representative DL frameworks, and offers practical guidance for service providers to deploying and delivering DL as a Service (DLaaS) and for application developers and DLaaS consumers to select the right DL frameworks for the right DL workloads.