 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Systematic Generalization in Grounded Language Understanding
Paper and Code
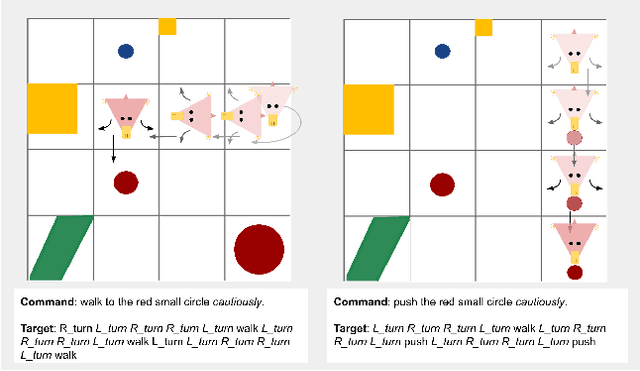

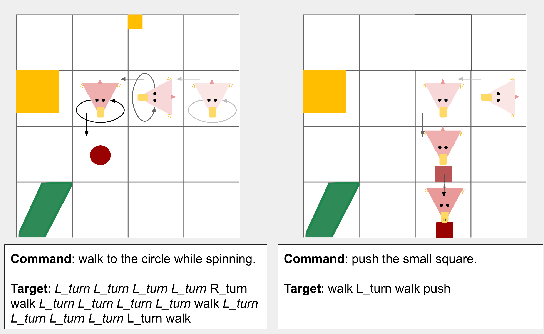
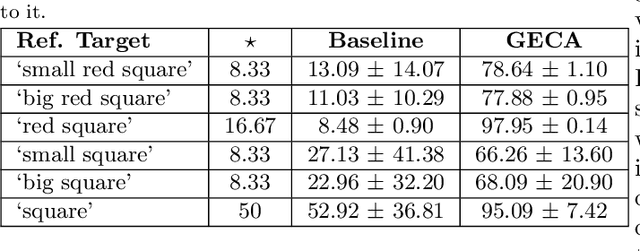
Human language users easily interpret expressions that describe unfamiliar situations composed from familiar parts ("greet the pink brontosaurus by the ferris wheel"). Modern neural networks, by contrast, struggle to interpret compositions unseen in training. In this paper, we introduce a new benchmark, gSCAN, for evaluating compositional generalization in models of situated language understanding. We take inspiration from standard models of meaning composition in formal linguistics. Going beyond an earlier related benchmark that focused on syntactic aspects of generalization, gSCAN defines a language grounded in the states of a grid world. This allows us to build novel generalization tasks that probe the acquisition of linguistically motivated rules. For example, agents must understand how adjectives such as 'small' are interpreted relative to the current world state or how adverbs such as 'cautiously' combine with new verbs. We test a strong multi-modal baseline model and a state-of-the-art compositional method finding that, in most cases, they fail dramatically when generalization requires systematic compositional rules.