 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DQ: Compact Quantized Neural Networks for Volumetric Whole Brain Segmentation
Paper and Code
Apr 16, 2019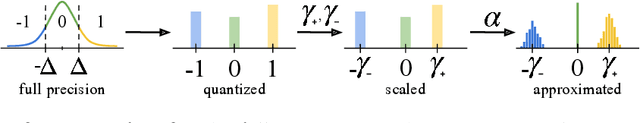



Model architectures have been dramatically increasing in size, improving performance at the cost of resource requirements. In this paper we propose 3DQ, a ternary quantization method, applied for the first time to 3D Fully Convolutional Neural Networks (F-CNNs), enabling 16x model compression while maintaining performance on par with full precision models. We extensively evaluate 3DQ on two datasets for the challenging task of whole brain segmentation. Additionally, we showcase our method's ability to generalize on two common 3D architectures, namely 3D U-Net and V-Net. Outperforming a variety of baselines, the proposed method is capable of compressing large 3D models to a few MBytes, alleviating the storage needs in space critical applications.