 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DMotion-Net: Learning Continuous Flow Function for 3D Motion Prediction
Paper and Code
Jun 24, 2020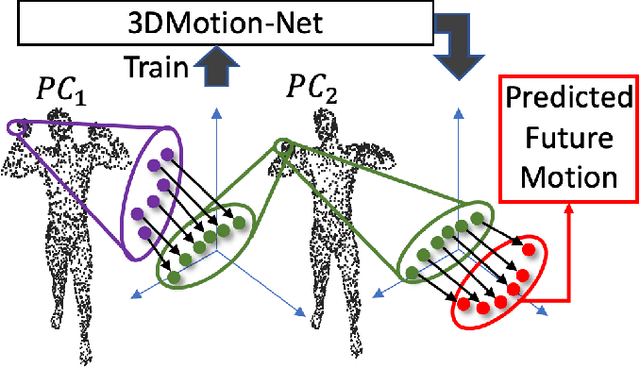
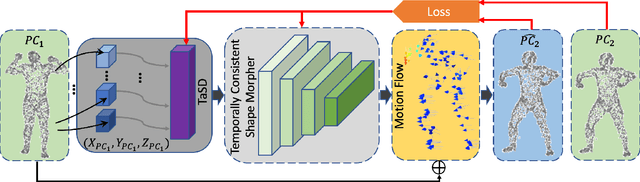
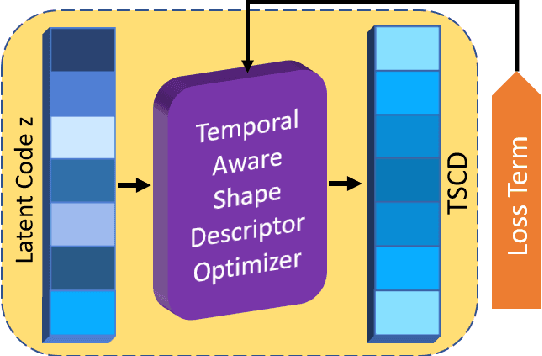
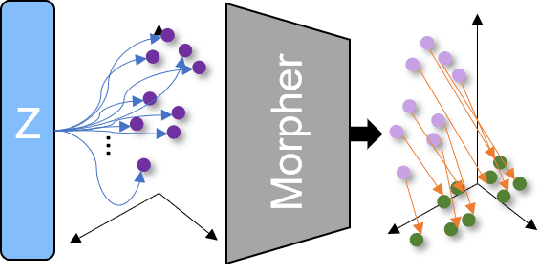
In this paper, we deal with the problem to predict the future 3D motions of 3D object scans from previous two consecutive frames. Previous methods mostly focus on sparse motion prediction in the form of skeletons. While in this paper we focus on predicting dense 3D motions in the from of 3D point clouds. To approach this problem, we propose a self-supervised approach that leverages the power of the deep neural network to learn a continuous flow function of 3D point clouds that can predict temporally consistent future motions and naturally bring out the correspondences among consecutive point clouds at the same time. More specifically, in our approach, to eliminate the unsolved and challenging process of defining a discrete point convolution on 3D point cloud sequences to encode spatial and temporal information, we introduce a learnable latent code to represent the temporal-aware shape descriptor which is optimized during model training. Moreover, a temporally consistent motion Morpher is proposed to learn a continuous flow field which deforms a 3D scan from the current frame to the next frame. We perform extensive experiments on D-FAUST, SCAPE and TOSCA benchmark data sets and the results demonstrate that our approach is capable of handling temporally inconsistent input and produces consistent future 3D motion while requiring no ground truth supervision.