 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Segmentation Learning from Sparse Annotations and Hierarchical Descriptors
Paper and Code
Jun 06, 2021
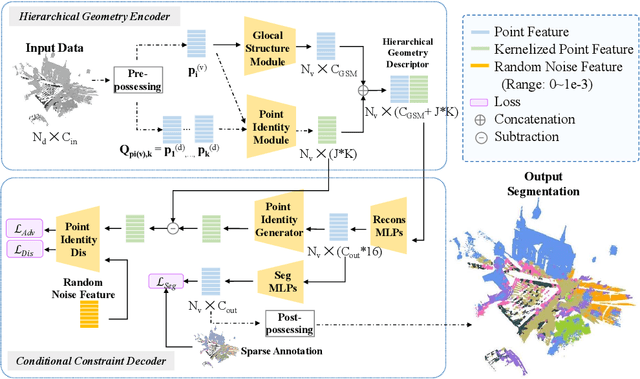
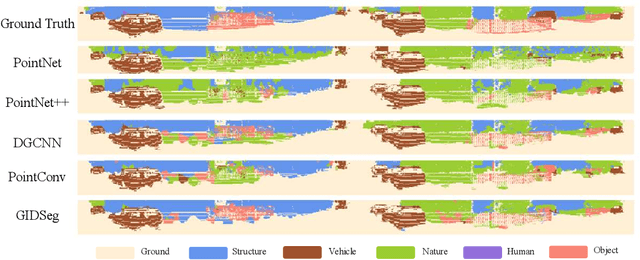
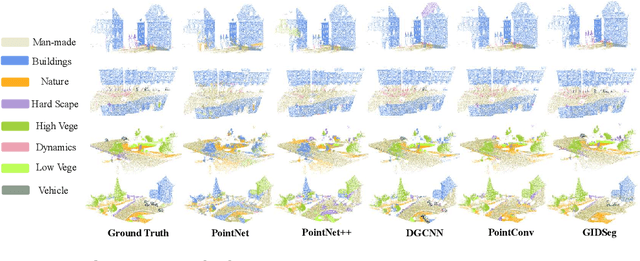
One of the main obstacles to 3D semantic segmentation is the significant amount of endeavor required to generate expensive point-wise annotations for fully supervised training. To alleviate manual efforts, we propose GIDSeg, a novel approach that can simultaneously learn segmentation from sparse annotations via reasoning global-regional structures and individual-vicinal properties. GIDSeg depicts global- and individual- relation via a dynamic edge convolution network coupled with a kernelized identity descriptor. The ensemble effects are obtained by endowing a fine-grained receptive field to a low-resolution voxelized map. In our GIDSeg, an adversarial learning module is also designed to further enhance the conditional constraint of identity descriptors within the joint feature distribution. Despite the apparent simplicity, our proposed approach achieves superior performance over state-of-the-art for inferencing 3D dense segmentation with only sparse annotations. Particularly, with $5\%$ annotations of raw data, GIDSeg outperforms other 3D segmentation methods.