 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-FM GAN: Towards 3D-Controllable Face Manipulation
Paper and Code

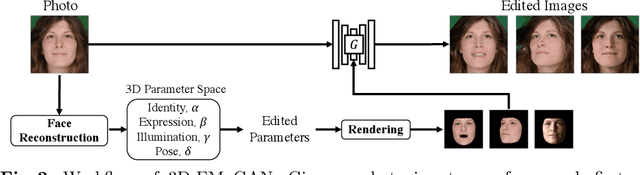

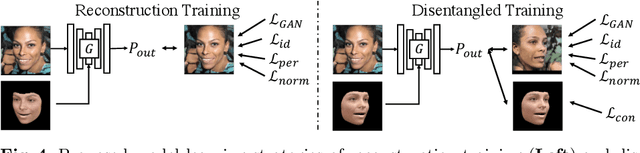
3D-controllable portrait synthesis has significantly advanced, thanks to breakthroughs in generative adversarial networks (GANs). However, it is still challenging to manipulate existing face images with precise 3D control. While concatenating GAN inversion and a 3D-aware, noise-to-image GAN is a straight-forward solution, it is inefficient and may lead to noticeable drop in editing quality. To fill this gap, we propose 3D-FM GAN, a novel conditional GAN framework designed specifically for 3D-controllable face manipulation, and does not require any tuning after the end-to-end learning phase. By carefully encoding both the input face image and a physically-based rendering of 3D edits into a StyleGAN's latent spaces, our image generator provides high-quality, identity-preserved, 3D-controllable face manipulation. To effectively learn such novel framework, we develop two essential training strategies and a novel multiplicative co-modulation architecture that improves significantly upon naive schemes. With extensive evaluations, we show that our method outperforms the prior arts on various tasks, with better editability, stronger identity preservation, and higher photo-realism. In addition, we demonstrate a better generalizability of our design on large pose editing and out-of-domain images.