 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMISNN: Multiple Imputation via Semi-parametric Neural Networks
May 02, 2023Multiple imputation (MI) has been widely applied to missing value problems in biomedical, social and econometric research, in order to avoid improper inference in the downstream data analysis. In the presence of high-dimensional data, imputation models that include feature selection, especially $\ell_1$ regularized regression (such as Lasso, adaptive Lasso, and Elastic Net), are common choices to prevent the model from underdetermination. However, conducting MI with feature selection is difficult: existing methods are often computationally inefficient and poor in performance. We propose MISNN, a novel and efficient algorithm that incorporates feature selection for MI. Leveraging the approximation power of neural networks, MISNN is a general and flexible framework, compatible with any feature selection method, any neural network architecture, high/low-dimensional data and general missing patterns. Through empirical experiments, MISNN has demonstrated great advantages over state-of-the-art imputation methods (e.g. Bayesian Lasso and matrix completion), in terms of imputation accuracy, statistical consistency and computation speed.
Multiple Imputation with Neural Network Gaussian Process for High-dimensional Incomplete Data
Nov 23, 2022



Missing data are ubiquitous in real world applications and, if not adequately handled, may lead to the loss of information and biased findings in downstream analysis. Particularly, high-dimensional incomplete data with a moderate sample size, such as analysis of multi-omics data, present daunting challenges. Imputation is arguably the most popular method for handling missing data, though existing imputation methods have a number of limitations. Single imputation methods such as matrix completion methods do not adequately account for imputation uncertainty and hence would yield improper statistical inference. In contrast, multiple imputation (MI) methods allow for proper inference but existing methods do not perform well in high-dimensional settings. Our work aims to address these significant methodological gaps, leveraging recent advances in neural network Gaussian process (NNGP) from a Bayesian viewpoint. We propose two NNGP-based MI methods, namely MI-NNGP, that can apply multiple imputations for missing values from a joint (posterior predictive) distribution. The MI-NNGP methods are shown to significantly outperform existing state-of-the-art methods on synthetic and real datasets, in terms of imputation error, statistical inference, robustness to missing rates, and computation costs, under three missing data mechanisms, MCAR, MAR, and MNAR.
Multiple Imputation via Generative Adversarial Network for High-dimensional Blockwise Missing Value Problems
Dec 21, 2021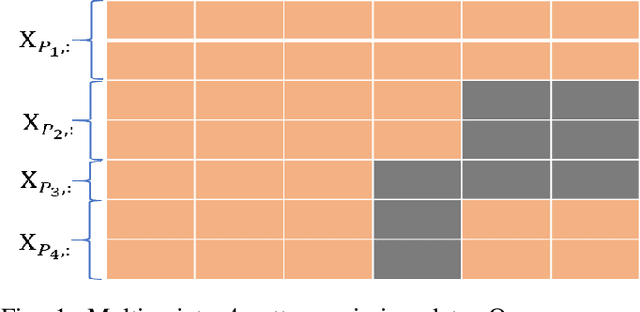

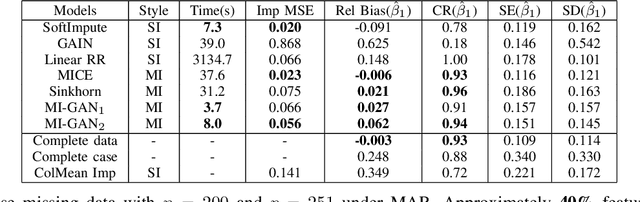

Missing data are present in most real world problems and need careful handling to preserve the prediction accuracy and statistical consistency in the downstream analysis. As the gold standard of handling missing data, multiple imputation (MI) methods are proposed to account for the imputation uncertainty and provide proper statistical inference. In this work, we propose Multiple Imputation via Generative Adversarial Network (MI-GAN), a deep learning-based (in specific, a GAN-based) multiple imputation method, that can work under missing at random (MAR) mechanism with theoretical support. MI-GAN leverages recent progress in conditional generative adversarial neural works and shows strong performance matching existing state-of-the-art imputation methods on high-dimensional datasets, in terms of imputation error. In particular, MI-GAN significantly outperforms other imputation methods in the sense of statistical inference and computational speed.