 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Supported Benchmark and Video Captioning for Basketball
Jan 25, 2024


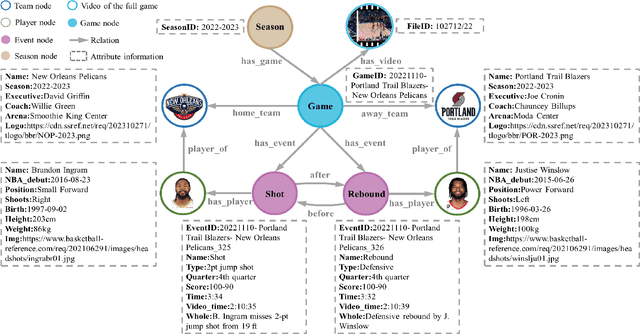
Despite the recent emergence of video captioning models, how to generate the text description with specific entity names and fine-grained actions is far from being solved, which however has great applications such as basketball live text broadcast. In this paper, a new multimodal knowledge supported basketball benchmark for video captioning is proposed. Specifically, we construct a Multimodal Basketball Game Knowledge Graph (MbgKG) to provide knowledge beyond videos. Then, a Multimodal Basketball Game Video Captioning (MbgVC) dataset that contains 9 types of fine-grained shooting events and 286 players' knowledge (i.e., images and names) is constructed based on MbgKG. We develop a novel framework in the encoder-decoder form named Entity-Aware Captioner (EAC) for basketball live text broadcast. The temporal information in video is encoded by introducing the bi-directional GRU (Bi-GRU) module. And the multi-head self-attention module is utilized to model the relationships among the players and select the key players. Besides, we propose a new performance evaluation metric named Game Description Score (GDS), which measures not only the linguistic performance but also the accuracy of the names prediction. Extensive experiments on MbgVC dataset demonstrate that EAC effectively leverages external knowledge and outperforms advanced video captioning models. The proposed benchmark and corresponding codes will be publicly available soon.