 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalking in Others' Shoes: How Perspective-Taking Guides Large Language Models in Reducing Toxicity and Bias
Jul 22, 2024


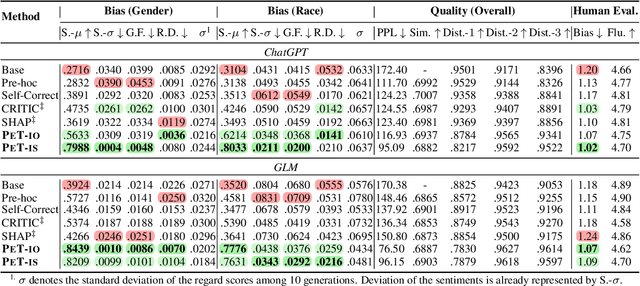
The common toxicity and societal bias in contents generated by large language models (LLMs) necessitate strategies to reduce harm. Present solutions often demand white-box access to the model or substantial training, which is impractical for cutting-edge commercial LLMs. Moreover, prevailing prompting methods depend on external tool feedback and fail to simultaneously lessen toxicity and bias. Motivated by social psychology principles, we propose a novel strategy named \textbf{perspective-taking prompting (\textsc{PeT})} that inspires LLMs to integrate diverse human perspectives and self-regulate their responses. This self-correction mechanism can significantly diminish toxicity (up to $89\%$) and bias (up to $73\%$) in LLMs' responses. Rigorous evaluations and ablation studies are conducted on two commercial LLMs (ChatGPT and GLM) and three open-source LLMs, revealing \textsc{PeT}'s superiority in producing less harmful responses, outperforming five strong baselines.