 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Anomaly Detection for Time Series Datasets
Jun 28, 2022
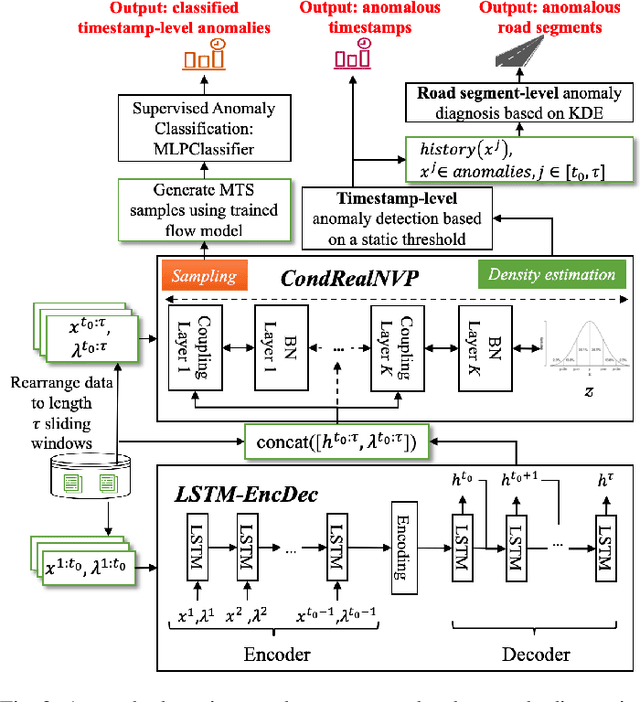

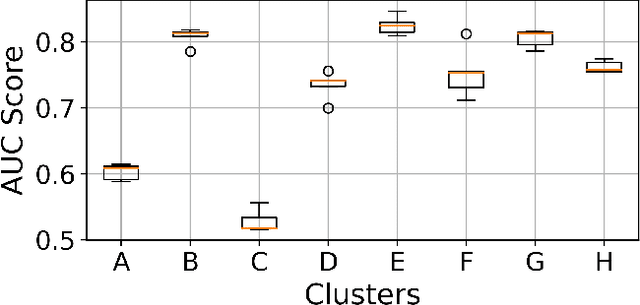
Traffic congestion anomaly detection is of paramount importance in intelligent traffic systems. The goals of transportation agencies are two-fold: to monitor the general traffic conditions in the area of interest and to locate road segments under abnormal congestion states. Modeling congestion patterns can achieve these goals for citywide roadways, which amounts to learning the distribution of multivariate time series (MTS). However, existing works are either not scalable or unable to capture the spatial-temporal information in MTS simultaneously. To this end, we propose a principled and comprehensive framework consisting of a data-driven generative approach that can perform tractable density estimation for detecting traffic anomalies. Our approach first clusters segments in the feature space and then uses conditional normalizing flow to identify anomalous temporal snapshots at the cluster level in an unsupervised setting. Then, we identify anomalies at the segment level by using a kernel density estimator on the anomalous cluster. Extensive experiments on synthetic datasets show that our approach significantly outperforms several state-of-the-art congestion anomaly detection and diagnosis methods in terms of Recall and F1-Score. We also use the generative model to sample labeled data, which can train classifiers in a supervised setting, alleviating the lack of labeled data for anomaly detection in sparse settings.
BARISTA: Efficient and Scalable Serverless Serving System for Deep Learning Prediction Services
Apr 11, 2019
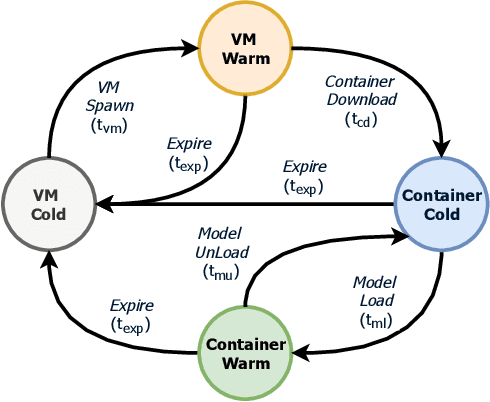
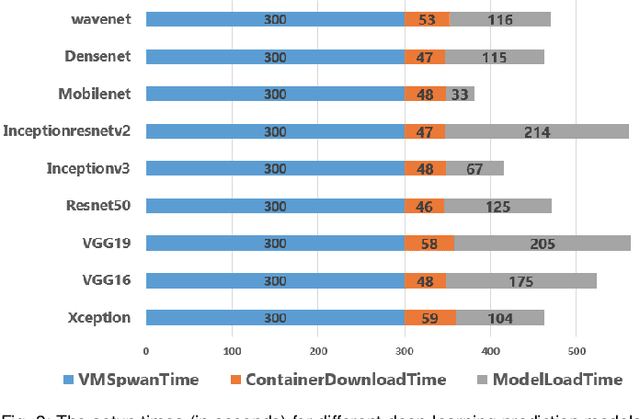
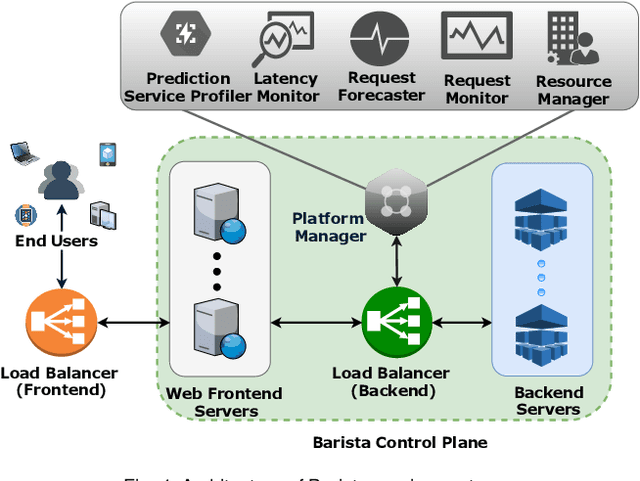
Pre-trained deep learning models are increasingly being used to offer a variety of compute-intensive predictive analytics services such as fitness tracking, speech and image recognition. The stateless and highly parallelizable nature of deep learning models makes them well-suited for serverless computing paradigm. However, making effective resource management decisions for these services is a hard problem due to the dynamic workloads and diverse set of available resource configurations that have their deployment and management costs. To address these challenges, we present a distributed and scalable deep-learning prediction serving system called Barista and make the following contributions. First, we present a fast and effective methodology for forecasting workloads by identifying various trends. Second, we formulate an optimization problem to minimize the total cost incurred while ensuring bounded prediction latency with reasonable accuracy. Third, we propose an efficient heuristic to identify suitable compute resource configurations. Fourth, we propose an intelligent agent to allocate and manage the compute resources by horizontal and vertical scaling to maintain the required prediction latency. Finally, using representative real-world workloads for urban transportation service, we demonstrate and validate the capabilities of Barista.