 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest arm identification in rare events
Mar 14, 2023We consider the best arm identification problem in the stochastic multi-armed bandit framework where each arm has a tiny probability of realizing large rewards while with overwhelming probability the reward is zero. A key application of this framework is in online advertising where click rates of advertisements could be a fraction of a single percent and final conversion to sales, while highly profitable, may again be a small fraction of the click rates. Lately, algorithms for BAI problems have been developed that minimise sample complexity while providing statistical guarantees on the correct arm selection. As we observe, these algorithms can be computationally prohibitive. We exploit the fact that the reward process for each arm is well approximated by a Compound Poisson process to arrive at algorithms that are faster, with a small increase in sample complexity. We analyze the problem in an asymptotic regime as rarity of reward occurrence reduces to zero, and reward amounts increase to infinity. This helps illustrate the benefits of the proposed algorithm. It also sheds light on the underlying structure of the optimal BAI algorithms in the rare event setting.
BARISTA: Efficient and Scalable Serverless Serving System for Deep Learning Prediction Services
Apr 11, 2019
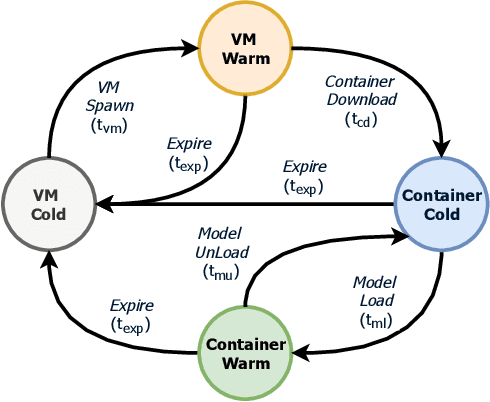
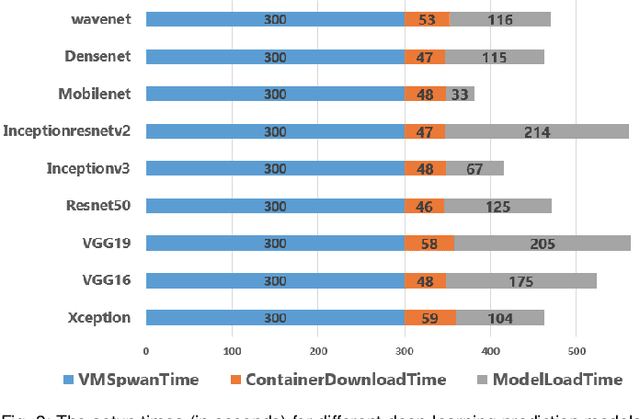
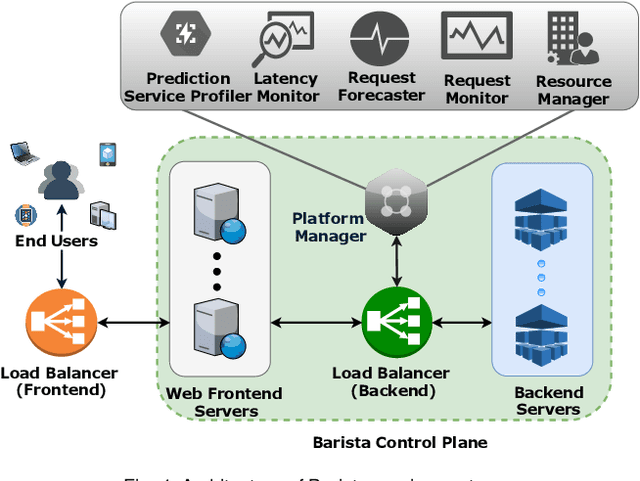
Pre-trained deep learning models are increasingly being used to offer a variety of compute-intensive predictive analytics services such as fitness tracking, speech and image recognition. The stateless and highly parallelizable nature of deep learning models makes them well-suited for serverless computing paradigm. However, making effective resource management decisions for these services is a hard problem due to the dynamic workloads and diverse set of available resource configurations that have their deployment and management costs. To address these challenges, we present a distributed and scalable deep-learning prediction serving system called Barista and make the following contributions. First, we present a fast and effective methodology for forecasting workloads by identifying various trends. Second, we formulate an optimization problem to minimize the total cost incurred while ensuring bounded prediction latency with reasonable accuracy. Third, we propose an efficient heuristic to identify suitable compute resource configurations. Fourth, we propose an intelligent agent to allocate and manage the compute resources by horizontal and vertical scaling to maintain the required prediction latency. Finally, using representative real-world workloads for urban transportation service, we demonstrate and validate the capabilities of Barista.
Stratum: A Serverless Framework for Lifecycle Management of Machine Learning based Data Analytics Tasks
Apr 03, 2019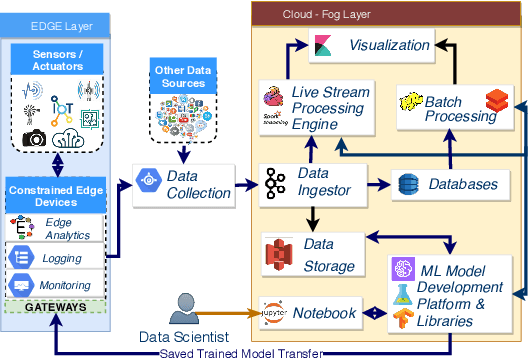
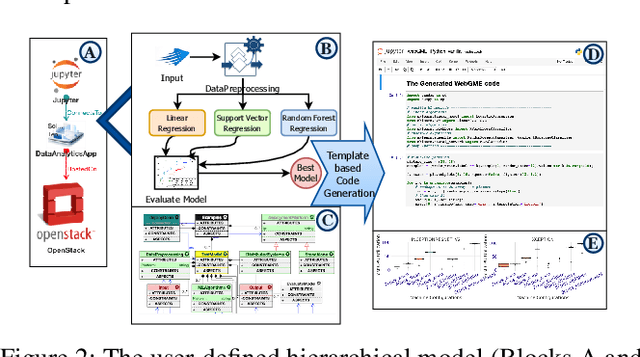
With the proliferation of machine learning (ML) libraries and frameworks, and the programming languages that they use, along with operations of data loading, transformation, preparation and mining, ML model development is becoming a daunting task. Furthermore, with a plethora of cloud-based ML model development platforms, heterogeneity in hardware, increased focus on exploiting edge computing resources for low-latency prediction serving and often a lack of a complete understanding of resources required to execute ML workflows efficiently, ML model deployment demands expertise for managing the lifecycle of ML workflows efficiently and with minimal cost. To address these challenges, we propose an end-to-end data analytics, a serverless platform called Stratum. Stratum can deploy, schedule and dynamically manage data ingestion tools, live streaming apps, batch analytics tools, ML-as-a-service (for inference jobs), and visualization tools across the cloud-fog-edge spectrum. This paper describes the Stratum architecture highlighting the problems it resolves.