 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpTimeGS: Sharp and Stable Dynamic Gaussian Splatting via Lifespan Modulation
Feb 03, 2026Novel view synthesis of dynamic scenes is fundamental to achieving photorealistic 4D reconstruction and immersive visual experiences. Recent progress in Gaussian-based representations has significantly improved real-time rendering quality, yet existing methods still struggle to maintain a balance between long-term static and short-term dynamic regions in both representation and optimization. To address this, we present SharpTimeGS, a lifespan-aware 4D Gaussian framework that achieves temporally adaptive modeling of both static and dynamic regions under a unified representation. Specifically, we introduce a learnable lifespan parameter that reformulates temporal visibility from a Gaussian-shaped decay into a flat-top profile, allowing primitives to remain consistently active over their intended duration and avoiding redundant densification. In addition, the learned lifespan modulates each primitives' motion, reducing drift in long-lived static points while retaining unrestricted motion for short-lived dynamic ones. This effectively decouples motion magnitude from temporal duration, improving long-term stability without compromising dynamic fidelity. Moreover, we design a lifespan-velocity-aware densification strategy that mitigates optimization imbalance between static and dynamic regions by allocating more capacity to regions with pronounced motion while keeping static areas compact and stable. Extensive experiments on multiple benchmarks demonstrate that our method achieves state-of-the-art performance while supporting real-time rendering up to 4K resolution at 100 FPS on one RTX 4090.
LSNet: Extremely Light-Weight Siamese Network For Change Detection in Remote Sensing Image
Jan 23, 2022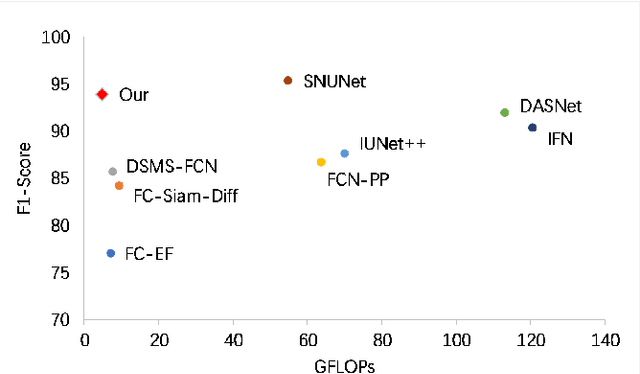



The Siamese network is becoming the mainstream in change detection of remote sensing images (RSI). However, in recent years, the development of more complicated structure, module and training processe has resulted in the cumbersome model, which hampers their application in large-scale RSI processing. To this end, this paper proposes an extremely lightweight Siamese network (LSNet) for RSI change detection, which replaces standard convolution with depthwise separable atrous convolution, and removes redundant dense connections, retaining only valid feature flows while performing Siamese feature fusion, greatly compressing parameters and computation amount. Compared with the first-place model on the CCD dataset, the parameters and the computation amount of LSNet is greatly reduced by 90.35\% and 91.34\% respectively, with only a 1.5\% drops in accuracy.